HBase简介
一、Hadoop的局限
HBase 是一个构建在 Hadoop 文件系统之上的面向列的数据库管理系统。
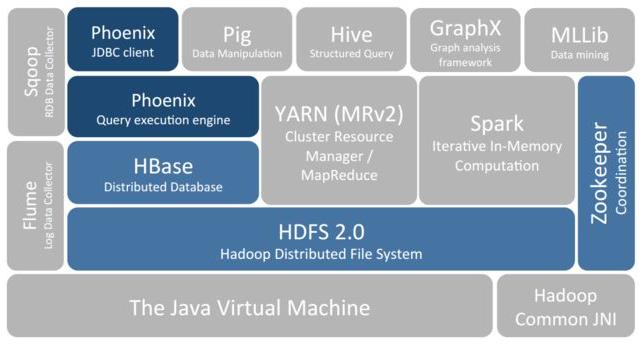
要想明白为什么产生 HBase,就需要先了解一下 Hadoop 存在的限制?Hadoop 可以通过 HDFS 来存储结构化、半结构甚至非结构化的数据,它是传统数据库的补充,是海量数据存储的最佳方法,它针对大文件的存储,批量访问和流式访问都做了优化,同时也通过多副本解决了容灾问题。
但是 Hadoop 的缺陷在于它只能执行批处理,并且只能以顺序方式访问数据,这意味着即使是最简单的工作,也必须搜索整个数据集,无法实现对数据的随机访问。实现数据的随机访问是传统的关系型数据库所擅长的,但它们却不能用于海量数据的存储。在这种情况下,必须有一种新的方案来解决海量数据存储和随机访问的问题,HBase 就是其中之一 (HBase,Cassandra,couchDB,Dynamo 和 MongoDB 都能存储海量数据并支持随机访问)。
注:数据结构分类:
- 结构化数据:即以关系型数据库表形式管理的数据;
- 半结构化数据:非关系模型的,有基本固定结构模式的数据,例如日志文件、XML 文档、JSON 文档、Email 等;
- 非结构化数据:没有固定模式的数据,如 WORD、PDF、PPT、EXL,各种格式的图片、视频等。
二、HBase简介
HBase 是一个构建在 Hadoop 文件系统之上的面向列的数据库管理系统。
HBase 是一种类似于 Google’s Big Table 的数据模型,它是 Hadoop 生态系统的一部分,它将数据存储在 HDFS 上,客户端可以通过 HBase 实现对 HDFS 上数据的随机访问。它具有以下特性:
- 不支持复杂的事务,只支持行级事务,即单行数据的读写都是原子性的;
- 由于是采用 HDFS 作为底层存储,所以和 HDFS 一样,支持结构化、半结构化和非结构化的存储;
- 支持通过增加机器进行横向扩展;
- 支持数据分片;
- 支持 RegionServers 之间的自动故障转移;
- 易于使用的 Java 客户端 API;
- 支持 BlockCache 和布隆过滤器;
- 过滤器支持谓词下推。
三、HBase Table
HBase 是一个面向 列 的数据库管理系统,这里更为确切的而说,HBase 是一个面向 列族 的数据库管理系统。表 schema 仅定义列族,表具有多个列族,每个列族可以包含任意数量的列,列由多个单元格(cell )组成,单元格可以存储多个版本的数据,多个版本数据以时间戳进行区分。
下图为 HBase 中一张表的:
- RowKey 为行的唯一标识,所有行按照 RowKey 的字典序进行排序;
- 该表具有两个列族,分别是 personal 和 office;
- 其中列族 personal 拥有 name、city、phone 三个列,列族 office 拥有 tel、addres 两个列。
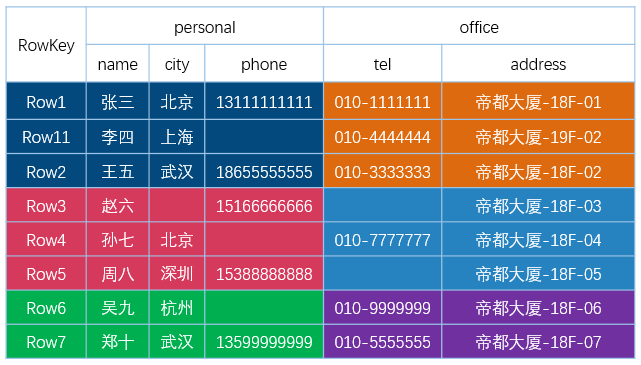
图片引用自 : HBase 是列式存储数据库吗 https://www.iteblog.com/archives/2498.html
Hbase 的表具有以下特点:
容量大:一个表可以有数十亿行,上百万列;
面向列:数据是按照列存储,每一列都单独存放,数据即索引,在查询时可以只访问指定列的数据,有效地降低了系统的 I/O 负担;
稀疏性:空 (null) 列并不占用存储空间,表可以设计的非常稀疏 ;
数据多版本:每个单元中的数据可以有多个版本,按照时间戳排序,新的数据在最上面;
存储类型:所有数据的底层存储格式都是字节数组 (byte[])。
四、Phoenix
Phoenix 是 HBase 的开源 SQL 中间层,它允许你使用标准 JDBC 的方式来操作 HBase 上的数据。在 Phoenix 之前,如果你要访问 HBase,只能调用它的 Java API,但相比于使用一行 SQL 就能实现数据查询,HBase 的 API 还是过于复杂。Phoenix 的理念是 we put sql SQL back in NOSQL,即你可以使用标准的 SQL 就能完成对 HBase 上数据的操作。同时这也意味着你可以通过集成 Spring Data JPA 或 Mybatis 等常用的持久层框架来操作 HBase。
其次 Phoenix 的性能表现也非常优异,Phoenix 查询引擎会将 SQL 查询转换为一个或多个 HBase Scan,通过并行执行来生成标准的 JDBC 结果集。它通过直接使用 HBase API 以及协处理器和自定义过滤器,可以为小型数据查询提供毫秒级的性能,为千万行数据的查询提供秒级的性能。同时 Phoenix 还拥有二级索引等 HBase 不具备的特性,因为以上的优点,所以 Phoenix 成为了 HBase 最优秀的 SQL 中间层。
参考资料
Hbase系统架构及数据结构
一、基本概念
一个典型的 Hbase Table 表如下:
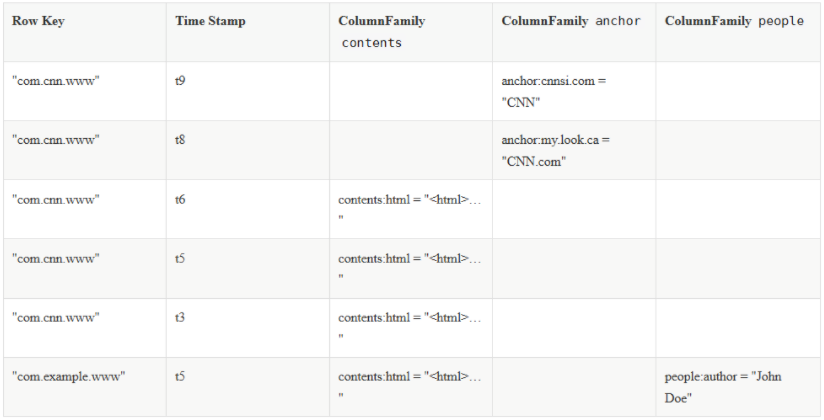
1.1 Row Key (行键)
Row Key 是用来检索记录的主键。想要访问 HBase Table 中的数据,只有以下三种方式:
通过指定的
Row Key进行访问;通过 Row Key 的 range 进行访问,即访问指定范围内的行;
进行全表扫描。
Row Key 可以是任意字符串,存储时数据按照 Row Key 的字典序进行排序。这里需要注意以下两点:
因为字典序对 Int 排序的结果是 1,10,100,11,12,13,14,15,16,17,18,19,2,20,21,…,9,91,92,93,94,95,96,97,98,99。如果你使用整型的字符串作为行键,那么为了保持整型的自然序,行键必须用 0 作左填充。
行的一次读写操作时原子性的 (不论一次读写多少列)。
1.2 Column Family(列族)
HBase 表中的每个列,都归属于某个列族。列族是表的 Schema 的一部分,所以列族需要在创建表时进行定义。列族的所有列都以列族名作为前缀,例如 courses:history,courses:math 都属于 courses 这个列族。
1.3 Column Qualifier (列限定符)
列限定符,你可以理解为是具体的列名,例如 courses:history,courses:math 都属于 courses 这个列族,它们的列限定符分别是 history 和 math。需要注意的是列限定符不是表 Schema 的一部分,你可以在插入数据的过程中动态创建列。
1.4 Column(列)
HBase 中的列由列族和列限定符组成,它们由 :(冒号) 进行分隔,即一个完整的列名应该表述为 列族名 :列限定符。
1.5 Cell
Cell 是行,列族和列限定符的组合,并包含值和时间戳。你可以等价理解为关系型数据库中由指定行和指定列确定的一个单元格,但不同的是 HBase 中的一个单元格是由多个版本的数据组成的,每个版本的数据用时间戳进行区分。
1.6 Timestamp(时间戳)
HBase 中通过 row key 和 column 确定的为一个存储单元称为 Cell。每个 Cell 都保存着同一份数据的多个版本。版本通过时间戳来索引,时间戳的类型是 64 位整型,时间戳可以由 HBase 在数据写入时自动赋值,也可以由客户显式指定。每个 Cell 中,不同版本的数据按照时间戳倒序排列,即最新的数据排在最前面。
二、存储结构
2.1 Regions
HBase Table 中的所有行按照 Row Key 的字典序排列。HBase Tables 通过行键的范围 (row key range) 被水平切分成多个 Region, 一个 Region 包含了在 start key 和 end key 之间的所有行。
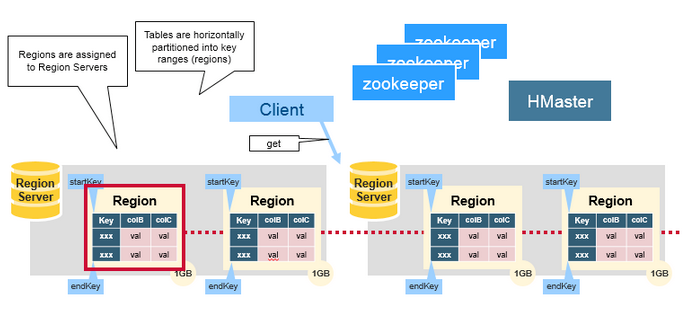
每个表一开始只有一个 Region,随着数据不断增加,Region 会不断增大,当增大到一个阀值的时候,Region 就会等分为两个新的 Region。当 Table 中的行不断增多,就会有越来越多的 Region。
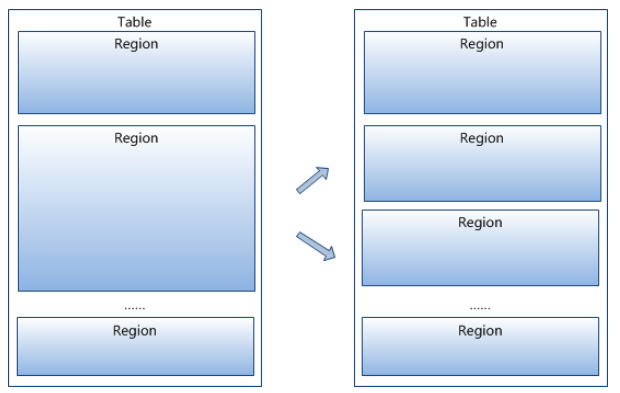
Region 是 HBase 中分布式存储和负载均衡的最小单元。这意味着不同的 Region 可以分布在不同的 Region Server 上。但一个 Region 是不会拆分到多个 Server 上的。
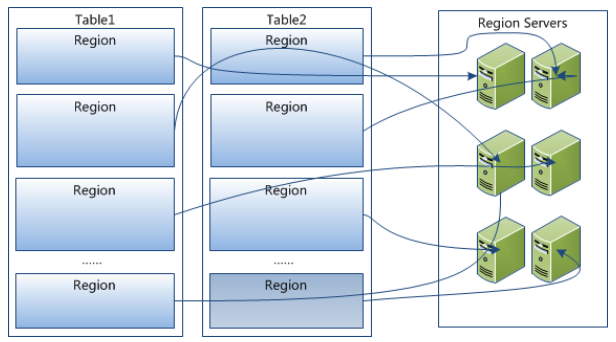
2.2 Region Server
Region Server 运行在 HDFS 的 DataNode 上。它具有以下组件:
- **WAL(Write Ahead Log,预写日志)**:用于存储尚未进持久化存储的数据记录,以便在发生故障时进行恢复。
- BlockCache:读缓存。它将频繁读取的数据存储在内存中,如果存储不足,它将按照
最近最少使用原则清除多余的数据。 - MemStore:写缓存。它存储尚未写入磁盘的新数据,并会在数据写入磁盘之前对其进行排序。每个 Region 上的每个列族都有一个 MemStore。
- HFile :将行数据按照 Key\Values 的形式存储在文件系统上。
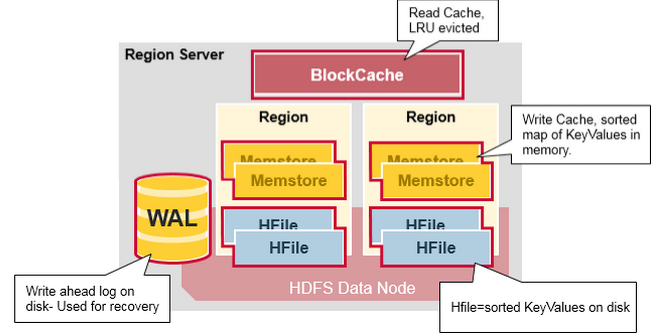
Region Server 存取一个子表时,会创建一个 Region 对象,然后对表的每个列族创建一个 Store 实例,每个 Store 会有 0 个或多个 StoreFile 与之对应,每个 StoreFile 则对应一个 HFile,HFile 就是实际存储在 HDFS 上的文件。
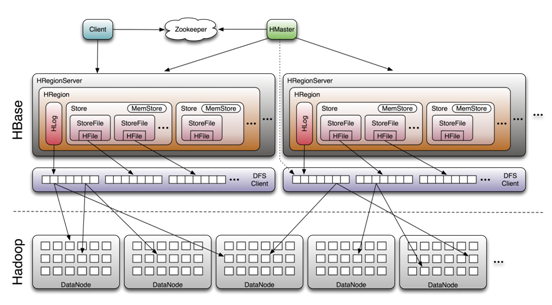
三、Hbase系统架构
3.1 系统架构
HBase 系统遵循 Master/Salve 架构,由三种不同类型的组件组成:
Zookeeper
保证任何时候,集群中只有一个 Master;
存贮所有 Region 的寻址入口;
实时监控 Region Server 的状态,将 Region Server 的上线和下线信息实时通知给 Master;
存储 HBase 的 Schema,包括有哪些 Table,每个 Table 有哪些 Column Family 等信息。
Master
为 Region Server 分配 Region ;
负责 Region Server 的负载均衡 ;
发现失效的 Region Server 并重新分配其上的 Region;
GFS 上的垃圾文件回收;
处理 Schema 的更新请求。
Region Server
Region Server 负责维护 Master 分配给它的 Region ,并处理发送到 Region 上的 IO 请求;
Region Server 负责切分在运行过程中变得过大的 Region。
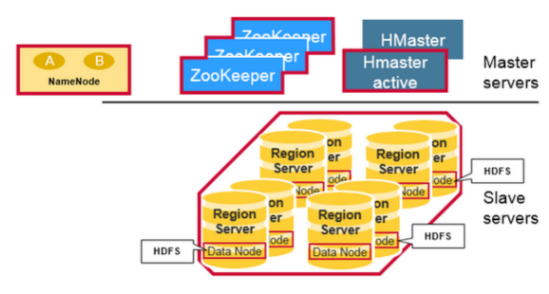
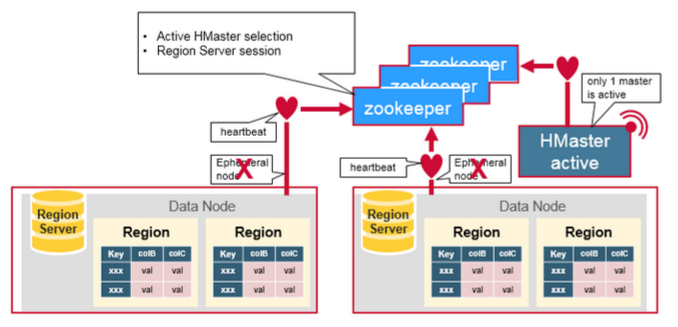
3.2 组件间的协作
HBase 使用 ZooKeeper 作为分布式协调服务来维护集群中的服务器状态。 Zookeeper 负责维护可用服务列表,并提供服务故障通知等服务:
每个 Region Server 都会在 ZooKeeper 上创建一个临时节点,Master 通过 Zookeeper 的 Watcher 机制对节点进行监控,从而可以发现新加入的 Region Server 或故障退出的 Region Server;
所有 Masters 会竞争性地在 Zookeeper 上创建同一个临时节点,由于 Zookeeper 只能有一个同名节点,所以必然只有一个 Master 能够创建成功,此时该 Master 就是主 Master,主 Master 会定期向 Zookeeper 发送心跳。备用 Masters 则通过 Watcher 机制对主 HMaster 所在节点进行监听;
如果主 Master 未能定时发送心跳,则其持有的 Zookeeper 会话会过期,相应的临时节点也会被删除,这会触发定义在该节点上的 Watcher 事件,使得备用的 Master Servers 得到通知。所有备用的 Master Servers 在接到通知后,会再次去竞争性地创建临时节点,完成主 Master 的选举。
四、数据的读写流程简述
4.1 写入数据的流程
Client 向 Region Server 提交写请求;
Region Server 找到目标 Region;
Region 检查数据是否与 Schema 一致;
如果客户端没有指定版本,则获取当前系统时间作为数据版本;
将更新写入 WAL Log;
将更新写入 Memstore;
判断 Memstore 存储是否已满,如果存储已满则需要 flush 为 Store Hfile 文件。
更为详细写入流程可以参考:HBase - 数据写入流程解析
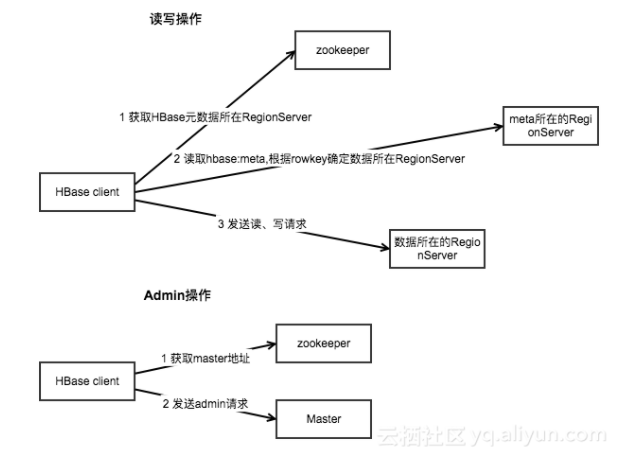
4.2 读取数据的流程
以下是客户端首次读写 HBase 上数据的流程:
客户端从 Zookeeper 获取
META表所在的 Region Server;客户端访问
META表所在的 Region Server,从META表中查询到访问行键所在的 Region Server,之后客户端将缓存这些信息以及META表的位置;客户端从行键所在的 Region Server 上获取数据。
如果再次读取,客户端将从缓存中获取行键所在的 Region Server。这样客户端就不需要再次查询 META 表,除非 Region 移动导致缓存失效,这样的话,则将会重新查询并更新缓存。
注:META 表是 HBase 中一张特殊的表,它保存了所有 Region 的位置信息,META 表自己的位置信息则存储在 ZooKeeper 上。
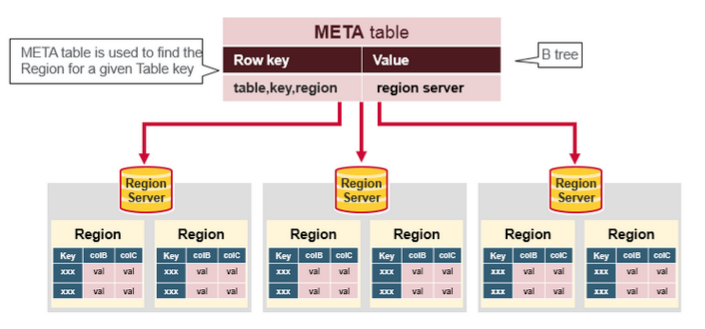
更为详细读取数据流程参考:
参考资料
本篇文章内容主要参考自官方文档和以下两篇博客,图片也主要引用自以下两篇博客:
官方文档:
Hbase 常用 Shell 命令
一、基本命令
打开 Hbase Shell:
1 | hbase shell |
1.1 获取帮助
1 | 获取帮助 |
1.2 查看服务器状态
1 | status |
1.3 查看版本信息
1 | version |
二、关于表的操作
2.1 查看所有表
1 | list |
2.2 创建表
命令格式: create ‘表名称’, ‘列族名称 1’,’列族名称 2’,’列名称 N’
1 | 创建一张名为Student的表,包含基本信息(baseInfo)、学校信息(schoolInfo)两个列族 |
2.3 查看表的基本信息
命令格式:desc ‘表名’
1 | describe 'Student' |
2.4 表的启用/禁用
enable 和 disable 可以启用/禁用这个表,is_enabled 和 is_disabled 来检查表是否被禁用
1 | 禁用表 |
2.5 检查表是否存在
1 | exists 'Student' |
2.6 删除表
1 | 删除表前需要先禁用表 |
三、增删改
3.1 添加列族
命令格式: alter ‘表名’, ‘列族名’
1 | alter 'Student', 'teacherInfo' |
3.2 删除列族
命令格式:alter ‘表名’, {NAME => ‘列族名’, METHOD => ‘delete’}
1 | alter 'Student', {NAME => 'teacherInfo', METHOD => 'delete'} |
3.3 更改列族存储版本的限制
默认情况下,列族只存储一个版本的数据,如果需要存储多个版本的数据,则需要修改列族的属性。修改后可通过 desc 命令查看。
1 | alter 'Student',{NAME=>'baseInfo',VERSIONS=>3} |
3.4 插入数据
命令格式:put ‘表名’, ‘行键’,’列族:列’,’值’
注意:如果新增数据的行键值、列族名、列名与原有数据完全相同,则相当于更新操作
1 | put 'Student', 'rowkey1','baseInfo:name','tom' |
3.5 获取指定行、指定行中的列族、列的信息
1 | 获取指定行中所有列的数据信息 |
3.6 删除指定行、指定行中的列
1 | 删除指定行(这句语法在2.2.7版本执行错误) |
四、查询
hbase 中访问数据有两种基本的方式:
按指定 rowkey 获取数据:get 方法;
按指定条件获取数据:scan 方法。
scan 可以设置 begin 和 end 参数来访问一个范围内所有的数据。get 本质上就是 begin 和 end 相等的一种特殊的 scan。
4.1Get查询
1 | 获取指定行中所有列的数据信息 |
4.2 查询整表数据
1 | scan 'Student' |
4.3 查询指定列簇的数据
1 | scan 'Student', {COLUMN=>'baseInfo'} |
4.4 条件查询
1 | 查询指定列的数据 |
除了列 (COLUMNS) 修饰词外,HBase 还支持 Limit(限制查询结果行数),STARTROW(ROWKEY 起始行,会先根据这个 key 定位到 region,再向后扫描)、STOPROW(结束行)、TIMERANGE(限定时间戳范围)、VERSIONS(版本数)、和 FILTER(按条件过滤行)等。
如下代表从 rowkey2 这个 rowkey 开始,查找下两个行的最新 3 个版本的 name 列的数据:
1 | scan 'Student', {COLUMNS=> 'baseInfo:name',STARTROW => 'rowkey2',STOPROW => 'wrowkey4',LIMIT=>2, VERSIONS=>3} |
4.5 条件过滤
Filter 可以设定一系列条件来进行过滤。如我们要查询值等于 24 的所有数据:
1 | scan 'Student', FILTER=>"ValueFilter(=,'binary:24')" |
值包含 yale 的所有数据:
1 | scan 'Student', FILTER=>"ValueFilter(=,'substring:yale')" |
列名中的前缀为 birth 的:
1 | scan 'Student', FILTER=>"ColumnPrefixFilter('birth')" |
FILTER 中支持多个过滤条件通过括号、AND 和 OR 进行组合:
1 | 列名中的前缀为birth且列值中包含1998的数据 |
PrefixFilter 用于对 Rowkey 的前缀进行判断:
1 | scan 'Student', FILTER=>"PrefixFilter('wr')" |
HBase Java API 的基本使用
一、简述
截至到目前 (2019.04),HBase 有两个主要的版本,分别是 1.x 和 2.x ,两个版本的 Java API 有所不同,1.x 中某些方法在 2.x 中被标识为 @deprecated 过时。所以下面关于 API 的样例,我会分别给出 1.x 和 2.x 两个版本。完整的代码见本仓库:
同时你使用的客户端的版本必须与服务端版本保持一致,如果用 2.x 版本的客户端代码去连接 1.x 版本的服务端,会抛出 NoSuchColumnFamilyException 等异常。
二、Java API 1.x 基本使用
2.1 新建Maven工程,导入项目依赖
要使用 Java API 操作 HBase,需要引入 hbase-client。这里选取的 HBase Client 的版本为 1.2.0。
1 | <dependency> |
2.2 API 基本使用
1 | public class HBaseUtils { |
2.3 单元测试
以单元测试的方式对上面封装的 API 进行测试。
1 | public class HBaseUtilsTest { |
三、Java API 2.x 基本使用
3.1 新建Maven工程,导入项目依赖
这里选取的 HBase Client 的版本为最新的 2.1.4。
这里的版本需要尽量和HBase的版本保持一致
1 | <dependency> |
3.2 API 的基本使用
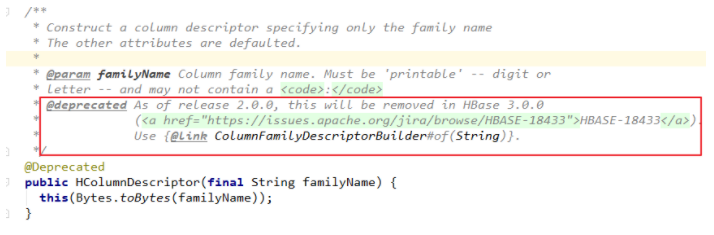
2.x 版本相比于 1.x 废弃了一部分方法,关于废弃的方法在源码中都会指明新的替代方法,比如,在 2.x 中创建表时:HTableDescriptor 和 HColumnDescriptor 等类都标识为废弃,取而代之的是使用 TableDescriptorBuilder 和 ColumnFamilyDescriptorBuilder 来定义表和列族。
报错:Caused by: java.net.ConnectException: Connection refused: no further information,java api无法连接HBase
解决方案:修改HBase服务器上的/etc/hosts文件。和IDE所在的Windows上的C:\Windows\System32\drivers\etc\hosts文件。上面的域名-ip解析列表中的项目值保持一致和准确。例如:
修改HBase服务器下的hosts文件:
1 | root@ubuntu:~# cat /etc/hosts |
修改Windows下的hosts文件:
1 | # C:\Windows\System32\drivers\etc\hosts |
以下为 HBase 2.x 版本 Java API 的使用示例:
1 | public class HBaseUtils { |
四、正确连接Hbase
在上面的代码中,在类加载时就初始化了 Connection 连接,并且之后的方法都是复用这个 Connection,这时我们可能会考虑是否可以使用自定义连接池来获取更好的性能表现?实际上这是没有必要的。
首先官方对于 Connection 的使用说明如下:
1 | Connection Pooling For applications which require high-end multithreaded |
之所以能这样使用,这是因为 Connection 并不是一个简单的 socket 连接,接口文档 中对 Connection 的表述是:
1 | A cluster connection encapsulating lower level individual connections to actual servers and a |
之所以封装这些连接,是因为 HBase 客户端需要连接三个不同的服务角色:
- Zookeeper :主要用于获取
meta表的位置信息,Master 的信息; - HBase Master :主要用于执行 HBaseAdmin 接口的一些操作,例如建表等;
- HBase RegionServer :用于读、写数据。
Connection 对象和实际的 Socket 连接之间的对应关系如下图:
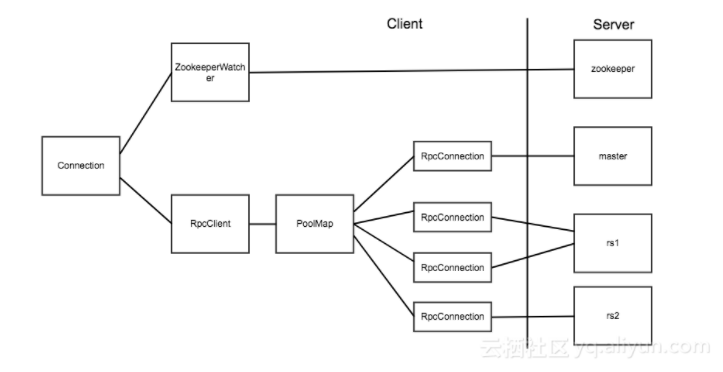
上面两张图片引用自博客:连接 HBase 的正确姿势
在 HBase 客户端代码中,真正对应 Socket 连接的是 RpcConnection 对象。HBase 使用 PoolMap 这种数据结构来存储客户端到 HBase 服务器之间的连接。PoolMap 的内部有一个 ConcurrentHashMap 实例,其 key 是 ConnectionId(封装了服务器地址和用户 ticket),value 是一个 RpcConnection 对象的资源池。当 HBase 需要连接一个服务器时,首先会根据 ConnectionId 找到对应的连接池,然后从连接池中取出一个连接对象。
1 | .Private |
HBase 中提供了三种资源池的实现,分别是 Reusable,RoundRobin 和 ThreadLocal。具体实现可以通 hbase.client.ipc.pool.type 配置项指定,默认为 Reusable。连接池的大小也可以通过 hbase.client.ipc.pool.size 配置项指定,默认为 1,即每个 Server 1 个连接。也可以通过修改配置实现:
1 | config.set("hbase.client.ipc.pool.type",...); |
由此可以看出 HBase 中 Connection 类已经实现了对连接的管理功能,所以我们不必在 Connection 上在做额外的管理。
另外,Connection 是线程安全的,但 Table 和 Admin 却不是线程安全的,因此正确的做法是一个进程共用一个 Connection 对象,而在不同的线程中使用单独的 Table 和 Admin 对象。Table 和 Admin 的获取操作 getTable() 和 getAdmin() 都是轻量级,所以不必担心性能的消耗,同时建议在使用完成后显示的调用 close() 方法来关闭它们。
参考资料
Hbase 过滤器详解
一、HBase过滤器简介
Hbase 提供了种类丰富的过滤器(filter)来提高数据处理的效率,用户可以通过内置或自定义的过滤器来对数据进行过滤,所有的过滤器都在服务端生效,即谓词下推(predicate push down)。这样可以保证过滤掉的数据不会被传送到客户端,从而减轻网络传输和客户端处理的压力。
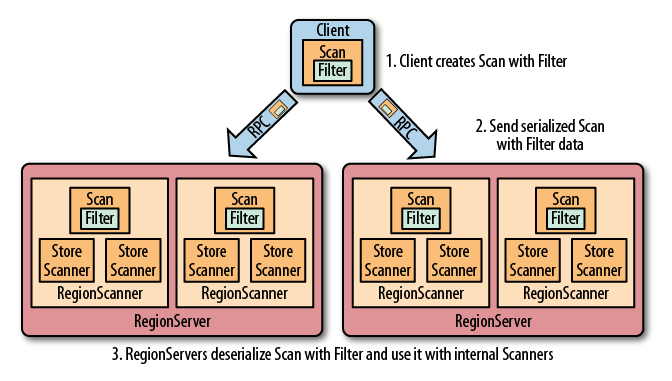
二、过滤器基础
2.1 Filter接口和FilterBase抽象类
Filter 接口中定义了过滤器的基本方法,FilterBase 抽象类实现了 Filter 接口。所有内置的过滤器则直接或者间接继承自 FilterBase 抽象类。用户只需要将定义好的过滤器通过 setFilter 方法传递给 Scan 或 put 的实例即可。
1 | setFilter(Filter filter) |
1 | // Scan 中定义的 setFilter |
1 | // Get 中定义的 setFilter |
FilterBase 的所有子类过滤器如下:
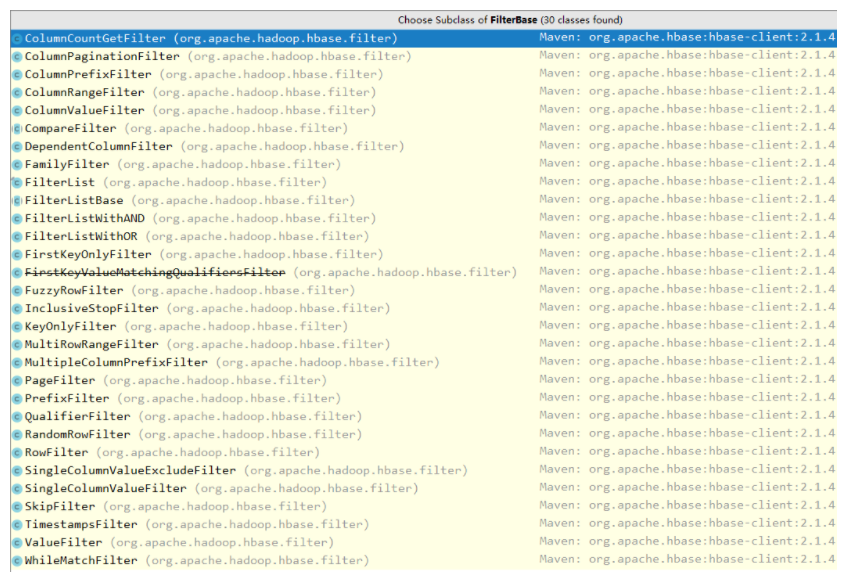
说明:上图基于当前时间点(2019.4)最新的 Hbase-2.1.4 ,下文所有说明均基于此版本。
2.2 过滤器分类
HBase 内置过滤器可以分为三类:分别是比较过滤器,专用过滤器和包装过滤器。分别在下面的三个小节中做详细的介绍。
三、比较过滤器
所有比较过滤器均继承自 CompareFilter。创建一个比较过滤器需要两个参数,分别是比较运算符和比较器实例。
1 | public CompareFilter(final CompareOp compareOp,final ByteArrayComparable comparator) { |
3.1 比较运算符
- LESS (<)
- LESS_OR_EQUAL (<=)
- EQUAL (=)
- NOT_EQUAL (!=)
- GREATER_OR_EQUAL (>=)
- GREATER (>)
- NO_OP (排除所有符合条件的值)
比较运算符均定义在枚举类 CompareOperator 中
1 | .Public |
注意:在 1.x 版本的 HBase 中,比较运算符定义在
CompareFilter.CompareOp枚举类中,但在 2.0 之后这个类就被标识为 @deprecated ,并会在 3.0 移除。所以 2.0 之后版本的 HBase 需要使用CompareOperator这个枚举类。
3.2 比较器
所有比较器均继承自 ByteArrayComparable 抽象类,常用的有以下几种:

- BinaryComparator : 使用
Bytes.compareTo(byte [],byte [])按字典序比较指定的字节数组。 - BinaryPrefixComparator : 按字典序与指定的字节数组进行比较,但只比较到这个字节数组的长度。
- RegexStringComparator : 使用给定的正则表达式与指定的字节数组进行比较。仅支持
EQUAL和NOT_EQUAL操作。 - SubStringComparator : 测试给定的子字符串是否出现在指定的字节数组中,比较不区分大小写。仅支持
EQUAL和NOT_EQUAL操作。 - NullComparator :判断给定的值是否为空。
- BitComparator :按位进行比较。
BinaryPrefixComparator 和 BinaryComparator 的区别不是很好理解,这里举例说明一下:
在进行 EQUAL 的比较时,如果比较器传入的是 abcd 的字节数组,但是待比较数据是 abcdefgh:
- 如果使用的是
BinaryPrefixComparator比较器,则比较以abcd字节数组的长度为准,即efgh不会参与比较,这时候认为abcd与abcdefgh是满足EQUAL条件的; - 如果使用的是
BinaryComparator比较器,则认为其是不相等的。
3.3 比较过滤器种类
比较过滤器共有五个(Hbase 1.x 版本和 2.x 版本相同),见下图:
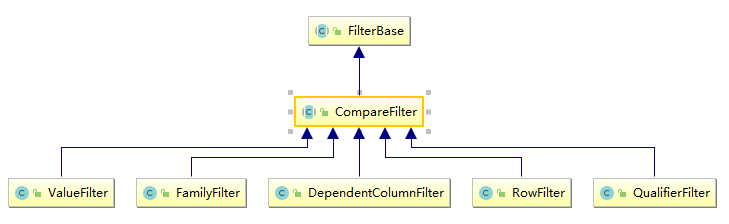
- RowFilter :基于行键来过滤数据;
- FamilyFilterr :基于列族来过滤数据;
- QualifierFilterr :基于列限定符(列名)来过滤数据;
- ValueFilterr :基于单元格 (cell) 的值来过滤数据;
- DependentColumnFilter :指定一个参考列来过滤其他列的过滤器,过滤的原则是基于参考列的时间戳来进行筛选 。
前四种过滤器的使用方法相同,均只要传递比较运算符和运算器实例即可构建,然后通过 setFilter 方法传递给 scan:
1 | Filter filter = new RowFilter(CompareOperator.LESS_OR_EQUAL, |
DependentColumnFilter 的使用稍微复杂一点,这里单独做下说明。
3.4 DependentColumnFilter
可以把 DependentColumnFilter 理解为一个 valueFilter 和一个时间戳过滤器的组合。DependentColumnFilter 有三个带参构造器,这里选择一个参数最全的进行说明:
1 | DependentColumnFilter(final byte [] family, final byte[] qualifier, |
- family :列族
- qualifier :列限定符(列名)
- dropDependentColumn :决定参考列是否被包含在返回结果内,为 true 时表示参考列被返回,为 false 时表示被丢弃
- op :比较运算符
- valueComparator :比较器
这里举例进行说明:
1 | DependentColumnFilter dependentColumnFilter = new DependentColumnFilter( |
首先会去查找
student:name中值以xiaolan开头的所有数据获得参考数据集,这一步等同于 valueFilter 过滤器;其次再用参考数据集中所有数据的时间戳去检索其他列,获得时间戳相同的其他列的数据作为
结果数据集,这一步等同于时间戳过滤器;最后如果
dropDependentColumn为 true,则返回参考数据集+结果数据集,若为 false,则抛弃参考数据集,只返回结果数据集。
四、专用过滤器
专用过滤器通常直接继承自 FilterBase,适用于范围更小的筛选规则。
4.1 单列列值过滤器 (SingleColumnValueFilter)
基于某列(参考列)的值决定某行数据是否被过滤。其实例有以下方法:
- setFilterIfMissing(boolean filterIfMissing) :默认值为 false,即如果该行数据不包含参考列,其依然被包含在最后的结果中;设置为 true 时,则不包含;
- setLatestVersionOnly(boolean latestVersionOnly) :默认为 true,即只检索参考列的最新版本数据;设置为 false,则检索所有版本数据。
1 | SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter( |
4.2 单列列值排除器 (SingleColumnValueExcludeFilter)
SingleColumnValueExcludeFilter 继承自上面的 SingleColumnValueFilter,过滤行为与其相反。
4.3 行键前缀过滤器 (PrefixFilter)
基于 RowKey 值决定某行数据是否被过滤。
1 | PrefixFilter prefixFilter = new PrefixFilter(Bytes.toBytes("xxx")); |
PrefixFilter是将rowkey前缀为指定字符串的数据全部过滤出来并返回给用户。例如:
1 | Scan scan = new Scan(); |
但是hbase的PrefixFilter比较粗暴,并没有根据filter做过多的查询优化。上述代码会scan整个区间的数据,得到一条数据就判断其是否符合前缀条件,不符合就读吓一条,直到找到前缀为def的数据。因此,我们可以指定一下startkey。
1 | Scan scan = new Scan(); |
4.4 列名前缀过滤器 (ColumnPrefixFilter)
基于列限定符(列名)决定某行数据是否被过滤。
用于列名(Qualifier)前缀过滤,即包含某个前缀的所有列名。
1 | ColumnPrefixFilter columnPrefixFilter = new ColumnPrefixFilter(Bytes.toBytes("xxx")); |
4.5 分页过滤器 (PageFilter)
可以使用这个过滤器实现对结果按行进行分页,创建 PageFilter 实例的时候需要传入每页的行数。
1 | public PageFilter(final long pageSize) { |
下面的代码体现了客户端实现分页查询的主要逻辑,这里对其进行一下解释说明:
客户端进行分页查询,需要传递 startRow(起始 RowKey),知道起始 startRow 后,就可以返回对应的 pageSize 行数据。这里唯一的问题就是,对于第一次查询,显然 startRow 就是表格的第一行数据,但是之后第二次、第三次查询我们并不知道 startRow,只能知道上一次查询的最后一条数据的 RowKey(简单称之为 lastRow)。
我们不能将 lastRow 作为新一次查询的 startRow 传入,因为 scan 的查询区间是[startRow,endRow) ,即前开后闭区间,这样 startRow 在新的查询也会被返回,这条数据就重复了。
同时在不使用第三方数据库存储 RowKey 的情况下,我们是无法通过知道 lastRow 的下一个 RowKey 的,因为 RowKey 的设计可能是连续的也有可能是不连续的。
由于 Hbase 的 RowKey 是按照字典序进行排序的。这种情况下,就可以在 lastRow 后面加上 0 ,作为 startRow 传入,因为按照字典序的规则,某个值加上 0 后的新值,在字典序上一定是这个值的下一个值,对于 HBase 来说下一个 RowKey 在字典序上一定也是等于或者大于这个新值的。
所以最后传入 lastRow+0,如果等于这个值的 RowKey 存在就从这个值开始 scan,否则从字典序的下一个 RowKey 开始 scan。
25 个字母以及数字字符,字典排序如下:
'0' < '1' < '2' < ... < '9' < 'a' < 'b' < ... < 'z'
分页查询主要实现逻辑:
1 | byte[] POSTFIX = new byte[] { 0x00 }; |
需要注意的是在多台 Regin Services 上执行分页过滤的时候,由于并行执行的过滤器不能共享它们的状态和边界,所以有可能每个过滤器都会在完成扫描前获取了 PageCount 行的结果,这种情况下会返回比分页条数更多的数据,分页过滤器就有失效的可能。
4.6 时间戳过滤器 (TimestampsFilter)
1 | List<Long> list = new ArrayList<>(); |
作用:过滤出对应时间戳的数据。
1 | private static void scanData() throws Exception { |
4.7 首次行键过滤器 (FirstKeyOnlyFilter)
FirstKeyOnlyFilter 只扫描每行的第一列,扫描完第一列后就结束对当前行的扫描,并跳转到下一行。相比于全表扫描,其性能更好,通常用于行数统计的场景,因为如果某一行存在,则行中必然至少有一列。
1 | FirstKeyOnlyFilter firstKeyOnlyFilter = new FirstKeyOnlyFilter(); |
五、包装过滤器
包装过滤器就是通过包装其他过滤器以实现某些拓展的功能。
5.1 SkipFilter过滤器
SkipFilter 包装一个过滤器,当被包装的过滤器遇到一个需要过滤的 KeyValue 实例时,则拓展过滤整行数据。下面是一个使用示例:
1 | // 定义 ValueFilter 过滤器 |
5.2 WhileMatchFilter过滤器
WhileMatchFilter 包装一个过滤器,当被包装的过滤器遇到一个需要过滤的 KeyValue 实例时,WhileMatchFilter 则结束本次扫描,返回已经扫描到的结果。下面是其使用示例:
1 | Filter filter1 = new RowFilter(CompareOperator.NOT_EQUAL, |
1 | :name/1555035006994/Put/vlen=8/seqid=0 |
可以看到被包装后,只返回了 rowKey4 之前的数据。
六、FilterList
以上都是讲解单个过滤器的作用,当需要多个过滤器共同作用于一次查询的时候,就需要使用 FilterList。FilterList 支持通过构造器或者 addFilter 方法传入多个过滤器。
1 | // 构造器传入 |
其中,public FilterList(final List<Filter> filters)源码为:
1 | public FilterList(List<Filter> filters) { |
多个过滤器组合的结果由 operator 参数定义 ,其可选参数定义在 Operator 枚举类中。只有 MUST_PASS_ALL 和 MUST_PASS_ONE 两个可选的值:
- MUST_PASS_ALL :相当于 AND,必须所有的过滤器都通过才认为通过;
- MUST_PASS_ONE :相当于 OR,只有要一个过滤器通过则认为通过。
1 | .Public |
使用示例如下:
1 | List<Filter> filters = new ArrayList<Filter>(); |
参考资料
HBase: The Definitive Guide _> Chapter 4. Client API: Advanced Features
Hbase 协处理器
一、简述
在使用 HBase 时,如果你的数据量达到了数十亿行或数百万列,此时能否在查询中返回大量数据将受制于网络的带宽,即便网络状况允许,但是客户端的计算处理也未必能够满足要求。在这种情况下,协处理器(Coprocessors)应运而生。它允许你将业务计算代码放入在 RegionServer 的协处理器中,将处理好的数据再返回给客户端,这可以极大地降低需要传输的数据量,从而获得性能上的提升。同时协处理器也允许用户扩展实现 HBase 目前所不具备的功能,如权限校验、二级索引、完整性约束等。
二、协处理器类型
2.1 Observer协处理器
1. 功能
Observer 协处理器类似于关系型数据库中的触发器,当发生某些事件的时候这类协处理器会被 Server 端调用。通常可以用来实现下面功能:
- 权限校验:在执行
Get或Put操作之前,您可以使用preGet或prePut方法检查权限; - 完整性约束: HBase 不支持关系型数据库中的外键功能,可以通过触发器在插入或者删除数据的时候,对关联的数据进行检查;
- 二级索引: 可以使用协处理器来维护二级索引。
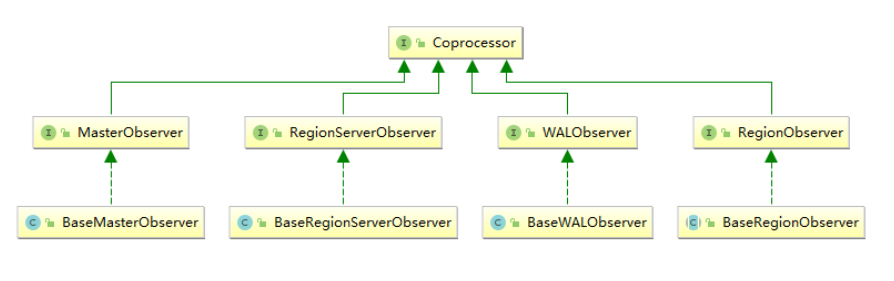
2. 类型
当前 Observer 协处理器有以下四种类型:
- RegionObserver :
允许您观察 Region 上的事件,例如 Get 和 Put 操作。 - RegionServerObserver :
允许您观察与 RegionServer 操作相关的事件,例如启动,停止或执行合并,提交或回滚。 - MasterObserver :
允许您观察与 HBase Master 相关的事件,例如表创建,删除或 schema 修改。 - WalObserver :
允许您观察与预写日志(WAL)相关的事件。
3. 接口
以上四种类型的 Observer 协处理器均继承自 Coprocessor 接口,这四个接口中分别定义了所有可用的钩子方法,以便在对应方法前后执行特定的操作。通常情况下,我们并不会直接实现上面接口,而是继承其 Base 实现类,Base 实现类只是简单空实现了接口中的方法,这样我们在实现自定义的协处理器时,就不必实现所有方法,只需要重写必要方法即可。
这里以 RegionObservers 为例,其接口类中定义了所有可用的钩子方法,下面截取了部分方法的定义,多数方法都是成对出现的,有 pre 就有 post:
4. 执行流程
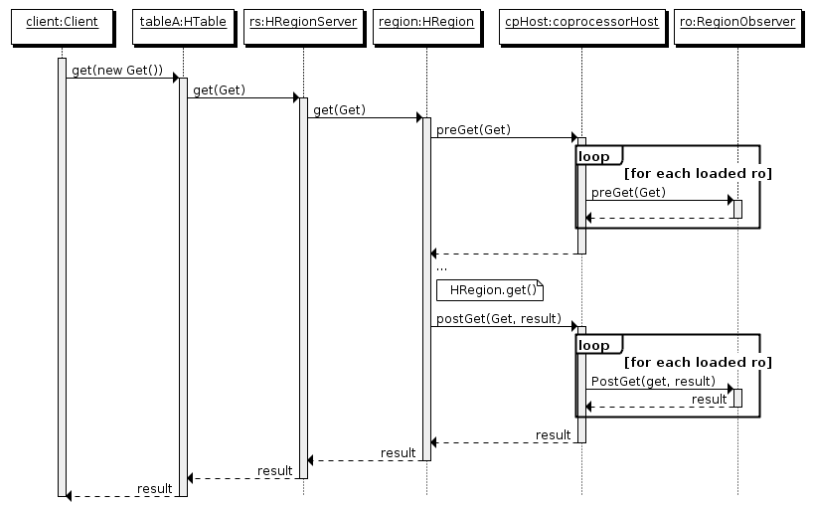
- 客户端发出 put 请求
- 该请求被分派给合适的 RegionServer 和 region
- coprocessorHost 拦截该请求,然后在该表的每个 RegionObserver 上调用 prePut()
- 如果没有被
prePut()拦截,该请求继续送到 region,然后进行处理 - region 产生的结果再次被 CoprocessorHost 拦截,调用
postPut() - 假如没有
postPut()拦截该响应,最终结果被返回给客户端
如果大家了解 Spring,可以将这种执行方式类比于其 AOP 的执行原理即可,官方文档当中也是这样类比的:
If you are familiar with Aspect Oriented Programming (AOP), you can think of a coprocessor as applying advice by intercepting a request and then running some custom code,before passing the request on to its final destination (or even changing the destination).
如果您熟悉面向切面编程(AOP),您可以将协处理器视为通过拦截请求然后运行一些自定义代码来使用 Advice,然后将请求传递到其最终目标(或者更改目标)。
2.2 Endpoint协处理器
Endpoint 协处理器类似于关系型数据库中的存储过程。客户端可以调用 Endpoint 协处理器在服务端对数据进行处理,然后再返回。
以聚集操作为例,如果没有协处理器,当用户需要找出一张表中的最大数据,即 max 聚合操作,就必须进行全表扫描,然后在客户端上遍历扫描结果,这必然会加重了客户端处理数据的压力。利用 Coprocessor,用户可以将求最大值的代码部署到 HBase Server 端,HBase 将利用底层 cluster 的多个节点并发执行求最大值的操作。即在每个 Region 范围内执行求最大值的代码,将每个 Region 的最大值在 Region Server 端计算出来,仅仅将该 max 值返回给客户端。之后客户端只需要将每个 Region 的最大值进行比较而找到其中最大的值即可。
三、协处理的加载方式
要使用我们自己开发的协处理器,必须通过静态(使用 HBase 配置)或动态(使用 HBase Shell 或 Java API)加载它。
- 静态加载的协处理器称之为 System Coprocessor(系统级协处理器),作用范围是整个 HBase 上的所有表,需要重启 HBase 服务;
- 动态加载的协处理器称之为 Table Coprocessor(表处理器),作用于指定的表,不需要重启 HBase 服务。
其加载和卸载方式分别介绍如下。
四、静态加载与卸载
4.1 静态加载
静态加载分以下三步:
- 在
hbase-site.xml定义需要加载的协处理器。
1 | <property> |
<name> 标签的值必须是下面其中之一:
- RegionObservers 和 Endpoints 协处理器:
hbase.coprocessor.region.classes - WALObservers 协处理器:
hbase.coprocessor.wal.classes - MasterObservers 协处理器:
hbase.coprocessor.master.classes
<value> 必须是协处理器实现类的全限定类名。如果为加载指定了多个类,则类名必须以逗号分隔。
将 jar(包含代码和所有依赖项) 放入 HBase 安装目录中的
lib目录下;重启 HBase。
4.2 静态卸载
从 hbase-site.xml 中删除配置的协处理器的<property>元素及其子元素;
从类路径或 HBase 的 lib 目录中删除协处理器的 JAR 文件(可选);
重启 HBase。
五、动态加载与卸载
使用动态加载协处理器,不需要重新启动 HBase。但动态加载的协处理器是基于每个表加载的,只能用于所指定的表。
此外,在使用动态加载必须使表脱机(disable)以加载协处理器。动态加载通常有两种方式:Shell 和 Java API 。
以下示例基于两个前提:
- coprocessor.jar 包含协处理器实现及其所有依赖项。
- JAR 包存放在 HDFS 上的路径为:hdfs:// <namenode>:<port> / user / <hadoop-user> /coprocessor.jar
5.1 HBase Shell动态加载
- 使用 HBase Shell 禁用表
1 | hbase > disable 'tableName' |
- 使用如下命令加载协处理器
1 | hbase > alter 'tableName', METHOD => 'table_att', 'Coprocessor'=>'hdfs://<namenode>:<port>/ |
Coprocessor 包含由管道(|)字符分隔的四个参数,按顺序解释如下:
- JAR 包路径:通常为 JAR 包在 HDFS 上的路径。关于路径以下两点需要注意:
- 允许使用通配符,例如:
hdfs://<namenode>:<port>/user/<hadoop-user>/*.jar来添加指定的 JAR 包; - 可以使指定目录,例如:
hdfs://<namenode>:<port>/user/<hadoop-user>/,这会添加目录中的所有 JAR 包,但不会搜索子目录中的 JAR 包。 - 类名:协处理器的完整类名。
- 优先级:协处理器的优先级,遵循数字的自然序,即值越小优先级越高。可以为空,在这种情况下,将分配默认优先级值。
- 可选参数 :传递的协处理器的可选参数。
- 启用表
1 | hbase > enable 'tableName' |
- 验证协处理器是否已加载
1 | hbase > describe 'tableName' |
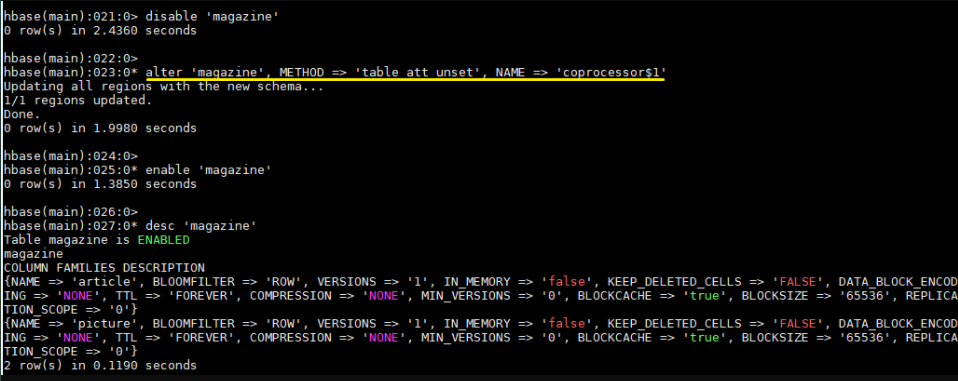
协处理器出现在 TABLE_ATTRIBUTES 属性中则代表加载成功。
5.2 HBase Shell动态卸载
- 禁用表
1 | disable 'tableName' |
- 移除表协处理器
1 | alter 'tableName', METHOD => 'table_att_unset', NAME => 'coprocessor$1' |
- 启用表
1 | enable 'tableName' |
5.3 Java API 动态加载
1 | TableName tableName = TableName.valueOf("users"); |
在 HBase 0.96 及其以后版本中,HTableDescriptor 的 addCoprocessor() 方法提供了一种更为简便的加载方法。
1 | TableName tableName = TableName.valueOf("users"); |
5.4 Java API 动态卸载
卸载其实就是重新定义表但不设置协处理器。这会删除所有表上的协处理器。
1 | TableName tableName = TableName.valueOf("users"); |
六、协处理器案例
这里给出一个简单的案例,实现一个类似于 Redis 中 append 命令的协处理器,当我们对已有列执行 put 操作时候,HBase 默认执行的是 update 操作,这里我们修改为执行 append 操作。
1 | redis append 命令示例 |
6.1 创建测试表
1 | 创建一张杂志表 有文章和图片两个列族 |
6.2 协处理器编程
完整代码可见本仓库:hbase-observer-coprocessor
新建 Maven 工程,导入下面依赖:
1 | <dependency> |
继承 BaseRegionObserver 实现我们自定义的 RegionObserver,对相同的 article:content 执行 put 命令时,将新插入的内容添加到原有内容的末尾,代码如下:
1 | public class AppendRegionObserver extends BaseRegionObserver { |
6.3 打包项目
使用 maven 命令进行打包,打包后的文件名为 hbase-observer-coprocessor-1.0-SNAPSHOT.jar
1 | mvn clean package |
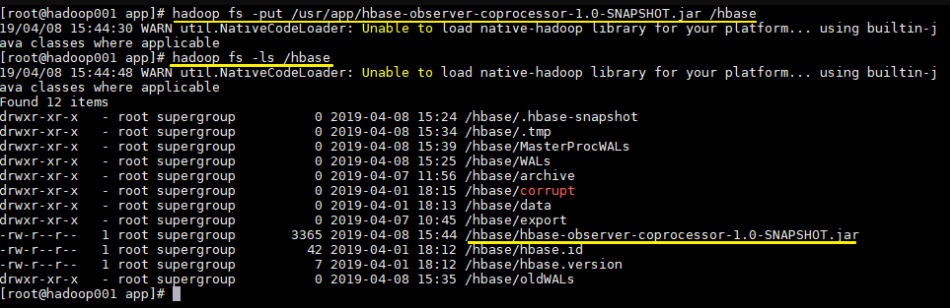
6.4 上传JAR包到HDFS
1 | 上传项目到HDFS上的hbase目录 |
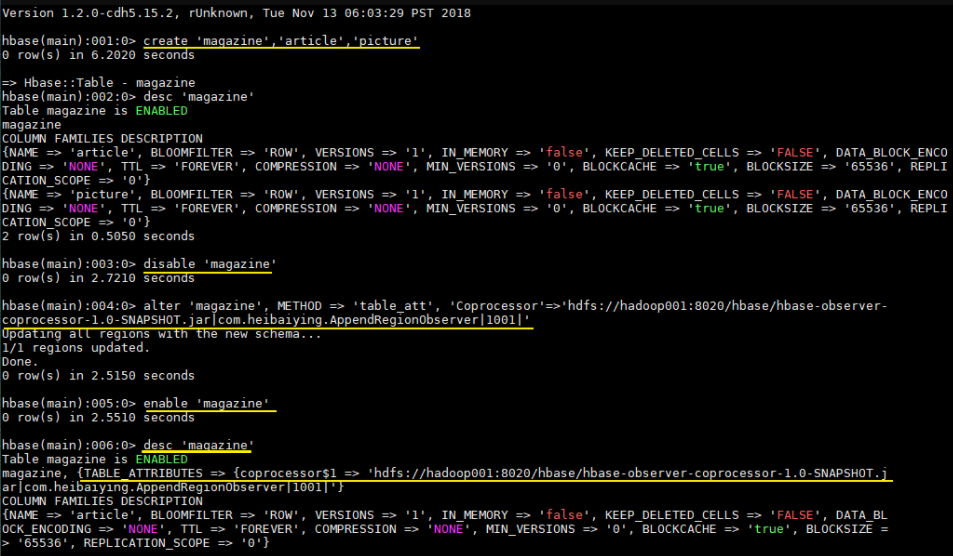
6.5 加载协处理器
- 加载协处理器前需要先禁用表
1 | hbase > disable 'magazine' |
- 加载协处理器
1 | hbase > alter 'magazine', METHOD => 'table_att', 'Coprocessor'=>'hdfs://hadoop001:8020/hbase/hbase-observer-coprocessor-1.0-SNAPSHOT.jar|com.heibaiying.AppendRegionObserver|1001|' |
- 启用表
1 | hbase > enable 'magazine' |
- 查看协处理器是否加载成功
1 | hbase > desc 'magazine' |
协处理器出现在 TABLE_ATTRIBUTES 属性中则代表加载成功,如下图:
6.6 测试加载结果
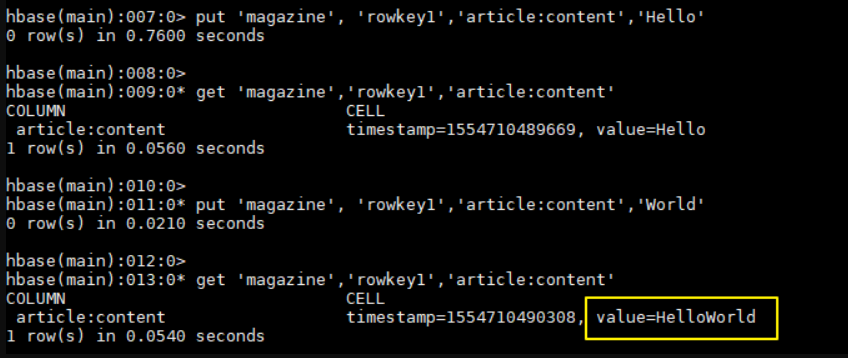
插入一组测试数据:
1 | hbase > put 'magazine', 'rowkey1','article:content','Hello' |
可以看到对于指定列的值已经执行了 append 操作:
插入一组对照数据:
1 | hbase > put 'magazine', 'rowkey1','article:author','zhangsan' |
可以看到对于正常的列还是执行 update 操作:
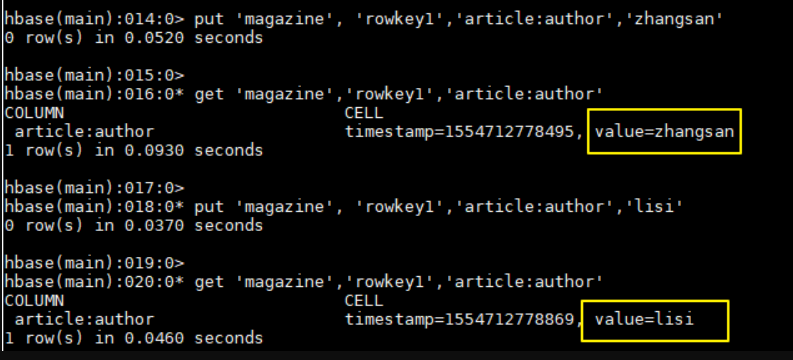
6.7 卸载协处理器
- 卸载协处理器前需要先禁用表
1 | hbase > disable 'magazine' |
- 卸载协处理器
1 | hbase > alter 'magazine', METHOD => 'table_att_unset', NAME => 'coprocessor$1' |
- 启用表
1 | hbase > enable 'magazine' |
- 查看协处理器是否卸载成功
1 | hbase > desc 'magazine' |
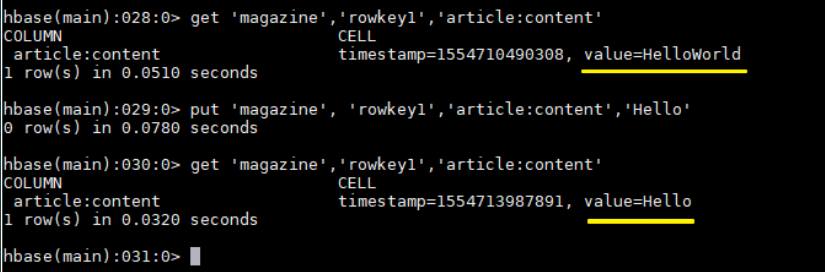
6.8 测试卸载结果
依次执行下面命令可以测试卸载是否成功
1 | hbase > get 'magazine','rowkey1','article:content' |
参考资料
Hbase容灾与备份
一、前言
本文主要介绍 Hbase 常用的三种简单的容灾备份方案,即CopyTable、Export/Import、Snapshot。分别介绍如下:
二、CopyTable
2.1 简介
CopyTable可以将现有表的数据复制到新表中,具有以下特点:
- 支持时间区间 、row 区间 、改变表名称 、改变列族名称 、以及是否 Copy 已被删除的数据等功能;
- 执行命令前,需先创建与原表结构相同的新表;
CopyTable的操作是基于 HBase Client API 进行的,即采用scan进行查询, 采用put进行写入。
2.2 命令格式
1 | Usage: CopyTable [general options] [--starttime=X] [--endtime=Y] [--new.name=NEW] [--peer.adr=ADR] <tablename> |
2.3 常用命令
先创建与原表结构相同的新表;
1 | create '表名称', '列族名称 1','列族名称 2','列名称 N' |
- 同集群下 CopyTable
1 | hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=tableCopy tableOrig |
- 不同集群下 CopyTable
1 | 两表名称相同的情况 |
- 下面是一个官方给的比较完整的例子,指定开始和结束时间,集群地址,以及只复制指定的列族:
1 | hbase org.apache.hadoop.hbase.mapreduce.CopyTable \ |
2.4 更多参数
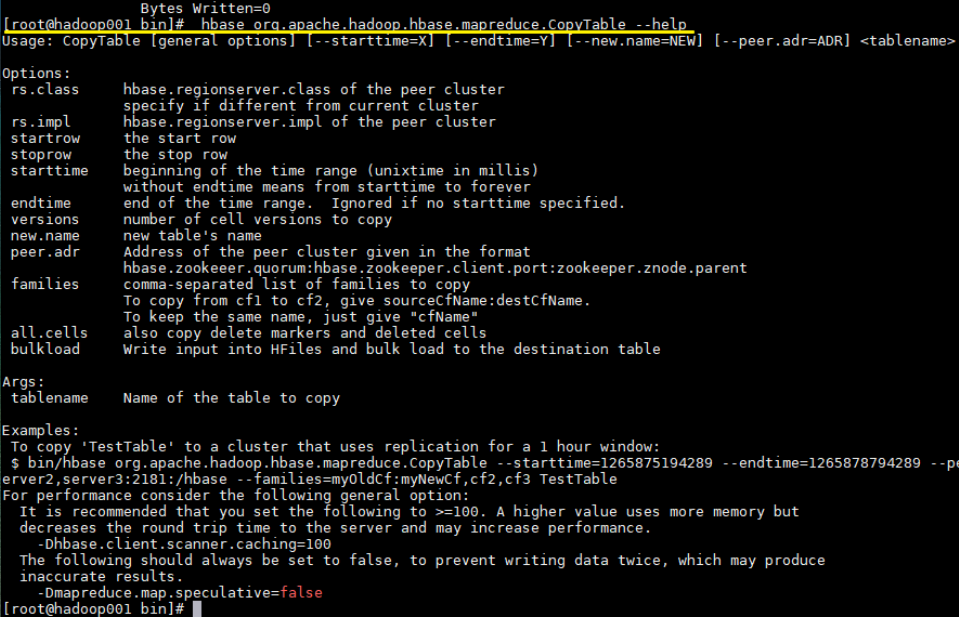
可以通过 --help 查看更多支持的参数
1 | hbase org.apache.hadoop.hbase.mapreduce.CopyTable --help |
三、Export/Import
3.1 简介
Export支持导出数据到 HDFS,Import支持从 HDFS 导入数据。Export还支持指定导出数据的开始时间和结束时间,因此可以用于增量备份。Export导出与CopyTable一样,依赖 HBase 的scan操作
3.2 命令格式
1 | Export |
- 导出的
outputdir目录可以不用预先创建,程序会自动创建。导出完成后,导出文件的所有权将由执行导出命令的用户所拥有。 - 默认情况下,仅导出给定
Cell的最新版本,而不管历史版本。要导出多个版本,需要将<versions>参数替换为所需的版本数。
3.3 常用命令
- 导出命令
1 | hbase org.apache.hadoop.hbase.mapreduce.Export 'tableName' <hdfs路径>/tableName.db |
例如:
1 | hbase org.apache.hadoop.hbase.mapreduce.Export 'Student' /usr/file/Student.db |
- 导入命令
执行导入,同样需要先创建表结构。
1 | hbase org.apache.hadoop.hbase.mapreduce.Import 'tableName' <hdfs路径>/tableName.db |
四、Snapshot
4.1 简介
HBase 的快照 (Snapshot) 功能允许您获取表的副本 (包括内容和元数据),并且性能开销很小。因为快照存储的仅仅是表的元数据和 HFiles 的信息。快照的 clone 操作会从该快照创建新表,快照的 restore 操作会将表的内容还原到快照节点。clone 和 restore 操作不需要复制任何数据,因为底层 HFiles(包含 HBase 表数据的文件) 不会被修改,修改的只是表的元数据信息。
4.2 配置
HBase在0.94版本开始提供了快照功能,0.95版本以后默认开启快照功能。
HBase 快照功能默认没有开启,如果要开启快照,需要在 hbase-site.xml 文件中添加如下配置项:
1 | <property> |
4.3 常用命令
快照的所有命令都需要在 Hbase Shell 交互式命令行中执行。
1. Take a Snapshot
1 | 拍摄快照 |
默认情况下拍摄快照之前会在内存中执行数据刷新。以保证内存中的数据包含在快照中。但是如果你不希望包含内存中的数据,则可以使用 SKIP_FLUSH 选项禁止刷新。
1 | 禁止内存刷新 |
2. Listing Snapshots
1 | 获取快照列表 |
3. Deleting Snapshots
1 | 删除快照 |
4. Clone a table from snapshot
1 | 从现有的快照创建一张新表 |
5. Restore a snapshot
将表恢复到快照节点,恢复操作需要先禁用表
1 | disable '表名' |
这里需要注意的是:是如果 HBase 配置了基于 Replication 的主从复制,由于 Replication 在日志级别工作,而快照在文件系统级别工作,因此在还原之后,会出现副本与主服务器处于不同的状态的情况。这时候可以先停止同步,所有服务器还原到一致的数据点后再重新建立同步。
参考资料
Hbase的SQL中间层——Phoenix
一、Phoenix简介
Phoenix 是 HBase 的开源 SQL 中间层,它允许你使用标准 JDBC 的方式来操作 HBase 上的数据。在 Phoenix 之前,如果你要访问 HBase,只能调用它的 Java API,但相比于使用一行 SQL 就能实现数据查询,HBase 的 API 还是过于复杂。Phoenix 的理念是 we put sql SQL back in NOSQL,即你可以使用标准的 SQL 就能完成对 HBase 上数据的操作。同时这也意味着你可以通过集成 Spring Data JPA 或 Mybatis 等常用的持久层框架来操作 HBase。
其次 Phoenix 的性能表现也非常优异,Phoenix 查询引擎会将 SQL 查询转换为一个或多个 HBase Scan,通过并行执行来生成标准的 JDBC 结果集。它通过直接使用 HBase API 以及协处理器和自定义过滤器,可以为小型数据查询提供毫秒级的性能,为千万行数据的查询提供秒级的性能。同时 Phoenix 还拥有二级索引等 HBase 不具备的特性,因为以上的优点,所以 Phoenix 成为了 HBase 最优秀的 SQL 中间层。
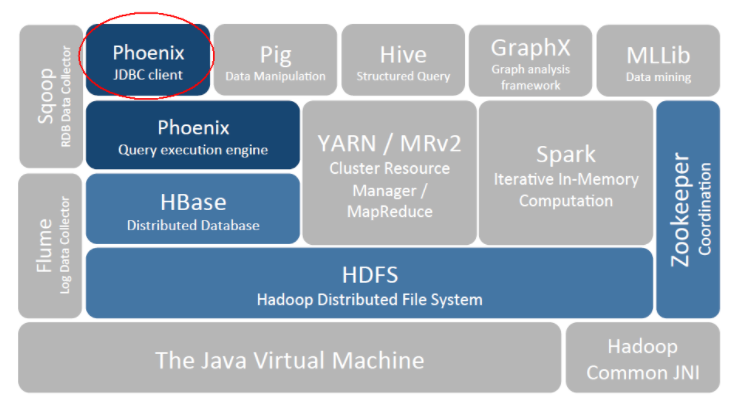
二、Phoenix安装
我们可以按照官方安装说明进行安装,官方说明如下:
- download and expand our installation tar
- copy the phoenix server jar that is compatible with your HBase installation into the lib directory of every region server
- restart the region servers
- add the phoenix client jar to the classpath of your HBase client
- download and setup SQuirrel as your SQL client so you can issue adhoc SQL against your HBase cluster
2.1 下载并解压
官方针对 Apache 版本和 CDH 版本的 HBase 均提供了安装包,按需下载即可。官方下载地址: http://phoenix.apache.org/download.html
1 | 下载 |
2.2 拷贝Jar包
按照官方文档的说明,需要将 phoenix server jar 添加到所有 Region Servers 的安装目录的 lib 目录下。
这里由于我搭建的是 HBase 伪集群,所以只需要拷贝到当前机器的 HBase 的 lib 目录下。如果是真实集群,则使用 scp 命令分发到所有 Region Servers 机器上。
1 | cp /usr/app/apache-phoenix-4.14.0-cdh5.14.2-bin/phoenix-4.14.0-cdh5.14.2-server.jar /usr/app/hbase-1.2.0-cdh5.15.2/lib |
2.3 重启 Region Servers
1 | 停止Hbase |
2.4 启动Phoenix
在 Phoenix 解压目录下的 bin 目录下执行如下命令,需要指定 Zookeeper 的地址:
- 如果 HBase 采用 Standalone 模式或者伪集群模式搭建,则默认采用内置的 Zookeeper 服务,端口为 2181;
- 如果是 HBase 是集群模式并采用外置的 Zookeeper 集群,则按照自己的实际情况进行指定。
1 | ./sqlline.py hadoop001:2181 |
2.5 启动结果
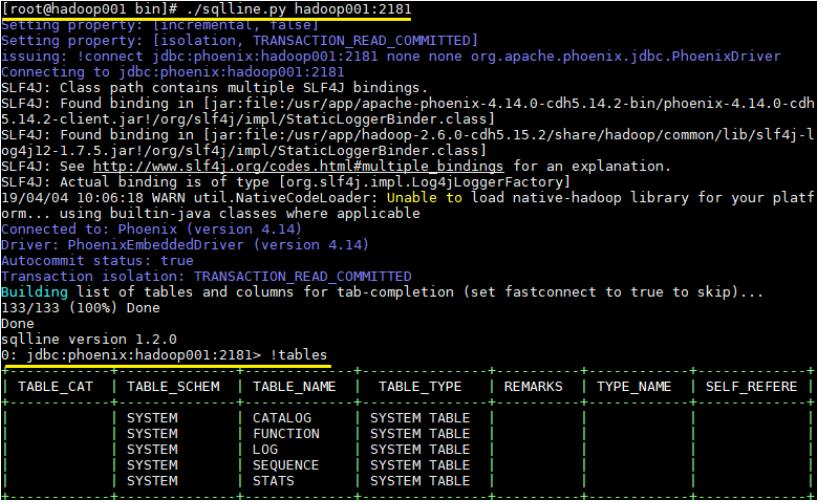
启动后则进入了 Phoenix 交互式 SQL 命令行,可以使用 !table 或 !tables 查看当前所有表的信息
三、Phoenix 简单使用
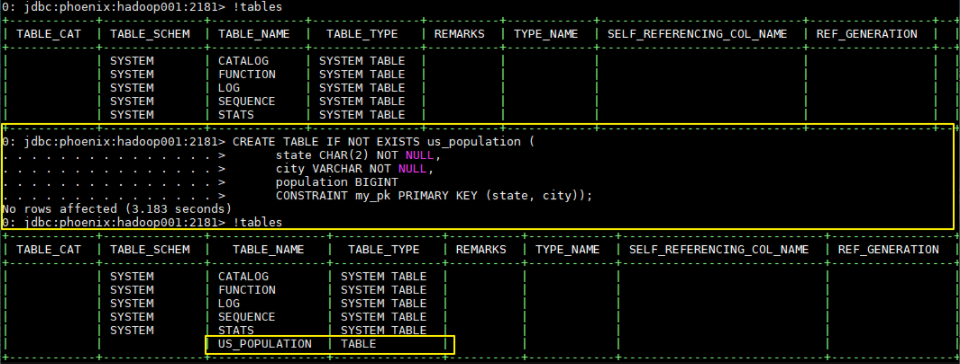
3.1 创建表
1 | CREATE TABLE IF NOT EXISTS us_population ( |
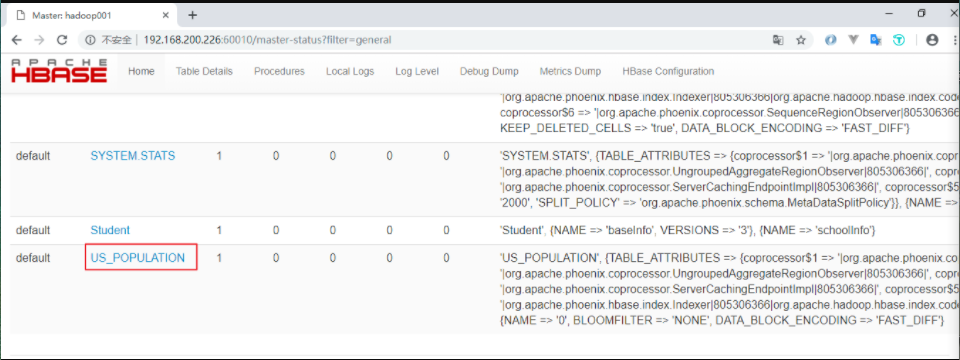
新建的表会按照特定的规则转换为 HBase 上的表,关于表的信息,可以通过 Hbase Web UI 进行查看:
3.2 插入数据
Phoenix 中插入数据采用的是 UPSERT 而不是 INSERT,因为 Phoenix 并没有更新操作,插入相同主键的数据就视为更新,所以 UPSERT 就相当于 UPDATE+INSERT
1 | UPSERT INTO us_population VALUES('NY','New York',8143197); |
3.3 修改数据
1 | -- 插入主键相同的数据就视为更新 |
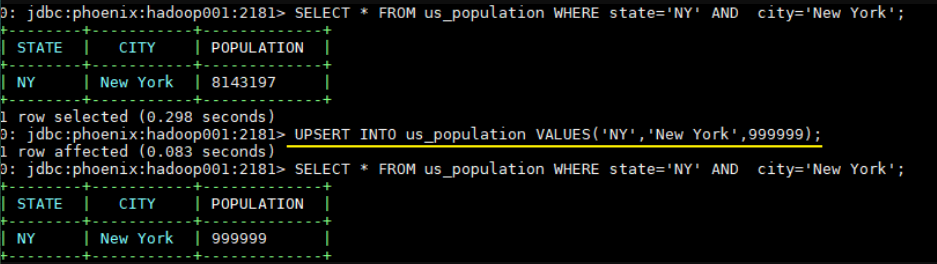
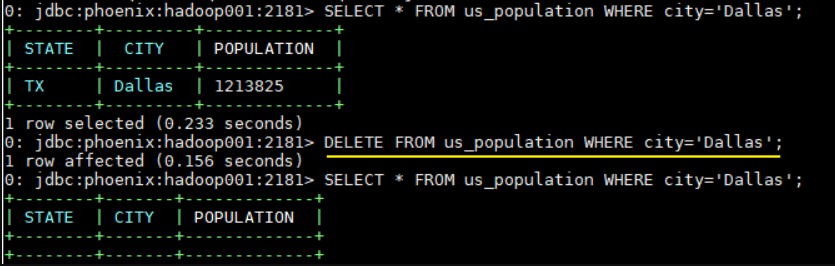
3.4 删除数据
1 | DELETE FROM us_population WHERE city='Dallas'; |
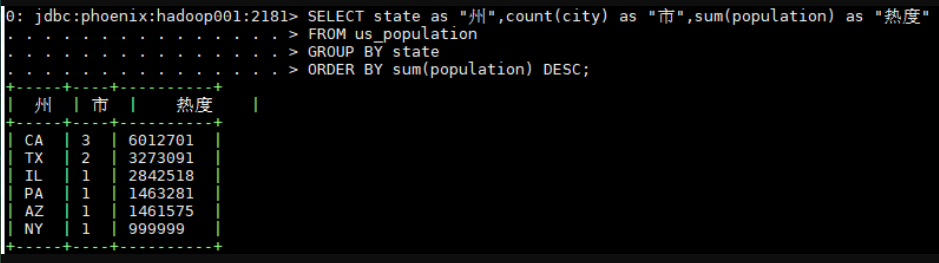
3.5 查询数据
1 | SELECT state as "州",count(city) as "市",sum(population) as "热度" |
3.6 退出命令
1 | !quit |
3.7 扩展
从上面的操作中可以看出,Phoenix 支持大多数标准的 SQL 语法。关于 Phoenix 支持的语法、数据类型、函数、序列等详细信息,因为涉及内容很多,可以参考其官方文档,官方文档上有详细的说明:
语法 (Grammar) :https://phoenix.apache.org/language/index.html
函数 (Functions) :http://phoenix.apache.org/language/functions.html
数据类型 (Datatypes) :http://phoenix.apache.org/language/datatypes.html
序列 (Sequences) :http://phoenix.apache.org/sequences.html
联结查询 (Joins) :http://phoenix.apache.org/joins.html
四、Phoenix Java API
因为 Phoenix 遵循 JDBC 规范,并提供了对应的数据库驱动 PhoenixDriver,这使得采用 Java 语言对其进行操作的时候,就如同对其他关系型数据库一样,下面给出基本的使用示例。
4.1 引入Phoenix core JAR包
如果是 maven 项目,直接在 maven 中央仓库找到对应的版本,导入依赖即可:
1 | <!-- https://mvnrepository.com/artifact/org.apache.phoenix/phoenix-core --> |
如果是普通项目,则可以从 Phoenix 解压目录下找到对应的 JAR 包,然后手动引入:
4.2 简单的Java API实例
1 | import java.sql.Connection; |
结果如下:
实际的开发中我们通常都是采用第三方框架来操作数据库,如 mybatis,Hibernate,Spring Data 等。关于 Phoenix 与这些框架的整合步骤参见下一篇文章:Spring/Spring Boot + Mybatis + Phoenix
参考资料
参考
- https://github.com/RealTommyHu/BigData-Notes/blob/master/notes/Hbase简介.md
- https://github.com/RealTommyHu/BigData-Notes/blob/master/notes/Hbase系统架构及数据结构.md
- https://github.com/RealTommyHu/BigData-Notes/blob/master/notes/Hbase_Shell.md
- https://github.com/RealTommyHu/BigData-Notes/blob/master/notes/Hbase_Java_API.md
- https://github.com/RealTommyHu/BigData-Notes/blob/master/notes/Hbase过滤器详解.md
- https://github.com/RealTommyHu/BigData-Notes/blob/master/notes/Hbase协处理器详解.md
- https://github.com/RealTommyHu/BigData-Notes/blob/master/notes/Hbase容灾与备份.md
- https://github.com/RealTommyHu/BigData-Notes/blob/master/notes/Hbase的SQL中间层_Phoenix.md