Hive简介及核心概念
一、简介
Hive 是一个构建在 Hadoop 之上的数据仓库,它可以将结构化的数据文件映射成表,并提供类 SQL 查询功能,用于查询的 SQL 语句会被转化为 MapReduce 作业,然后提交到 Hadoop 上运行。
特点:
- 简单、容易上手 (提供了类似 sql 的查询语言 hql),使得精通 sql 但是不了解 Java 编程的人也能很好地进行大数据分析;
- 灵活性高,可以自定义用户函数 (UDF) 和存储格式;
- 为超大的数据集设计的计算和存储能力,集群扩展容易;
- 统一的元数据管理,可与 presto/impala/sparksql 等共享数据;
- 执行延迟高,不适合做数据的实时处理,但适合做海量数据的离线处理。
二、Hive的体系架构
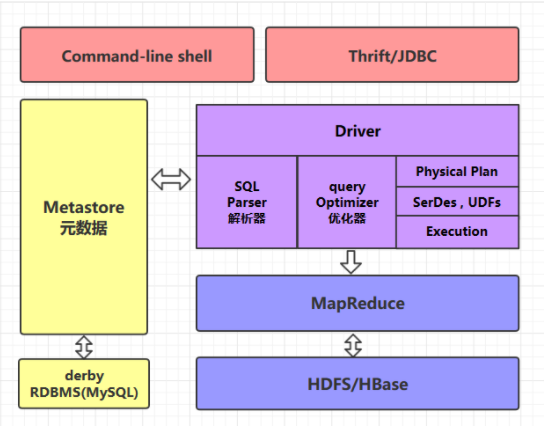
2.1 command-line shell & thrift/jdbc
可以用 command-line shell 和 thrift/jdbc 两种方式来操作数据:
- command-line shell:通过 hive 命令行的的方式来操作数据;
- thrift/jdbc:通过 thrift 协议按照标准的 JDBC 的方式操作数据。
2.2 Metastore
在 Hive 中,表名、表结构、字段名、字段类型、表的分隔符等统一被称为元数据。所有的元数据默认存储在 Hive 内置的 derby 数据库中,但由于 derby 只能有一个实例,也就是说不能有多个命令行客户端同时访问,所以在实际生产环境中,通常使用 MySQL 代替 derby。
Hive 进行的是统一的元数据管理,就是说你在 Hive 上创建了一张表,然后在 presto/impala/sparksql 中都是可以直接使用的,它们会从 Metastore 中获取统一的元数据信息,同样的你在 presto/impala/sparksql 中创建一张表,在 Hive 中也可以直接使用。
2.3 HQL的执行流程
Hive 在执行一条 HQL 的时候,会经过以下步骤:
- 语法解析:Antlr 定义 SQL 的语法规则,完成 SQL 词法,语法解析,将 SQL 转化为抽象 语法树 AST Tree;
- 语义解析:遍历 AST Tree,抽象出查询的基本组成单元 QueryBlock;
- 生成逻辑执行计划:遍历 QueryBlock,翻译为执行操作树 OperatorTree;
- 优化逻辑执行计划:逻辑层优化器进行 OperatorTree 变换,合并不必要的 ReduceSinkOperator,减少 shuffle 数据量;
- 生成物理执行计划:遍历 OperatorTree,翻译为 MapReduce 任务;
- 优化物理执行计划:物理层优化器进行 MapReduce 任务的变换,生成最终的执行计划。
关于 Hive SQL 的详细执行流程可以参考美团技术团队的文章:Hive SQL 的编译过程
三、数据类型
3.1 基本数据类型
Hive 表中的列支持以下基本数据类型:
| 大类 | 类型 |
|---|---|
| Integers(整型) | TINYINT—1 字节的有符号整数 SMALLINT—2 字节的有符号整数 INT—4 字节的有符号整数 BIGINT—8 字节的有符号整数 |
| Boolean(布尔型) | BOOLEAN—TRUE/FALSE |
| Floating point numbers(浮点型) | FLOAT— 单精度浮点型 DOUBLE—双精度浮点型 |
| Fixed point numbers(定点数) | DECIMAL—用户自定义精度定点数,比如 DECIMAL(7,2) |
| String types(字符串) | STRING—指定字符集的字符序列 VARCHAR—具有最大长度限制的字符序列 CHAR—固定长度的字符序列 |
| Date and time types(日期时间类型) | TIMESTAMP — 时间戳 TIMESTAMP WITH LOCAL TIME ZONE — 时间戳,纳秒精度 DATE—日期类型 |
| Binary types(二进制类型) | BINARY—字节序列 |
TIMESTAMP 和 TIMESTAMP WITH LOCAL TIME ZONE 的区别如下:
- TIMESTAMP WITH LOCAL TIME ZONE:用户提交时间给数据库时,会被转换成数据库所在的时区来保存。查询时则按照查询客户端的不同,转换为查询客户端所在时区的时间。
- TIMESTAMP :提交什么时间就保存什么时间,查询时也不做任何转换。
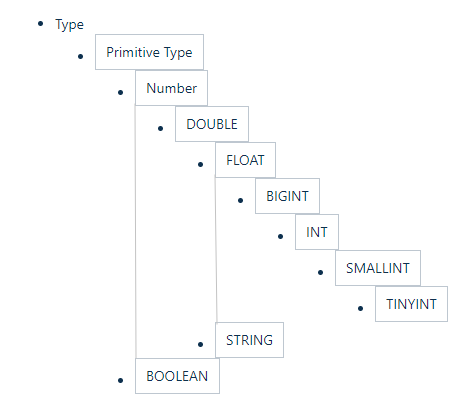
3.2 隐式转换
Hive 中基本数据类型遵循以下的层次结构,按照这个层次结构,子类型到祖先类型允许隐式转换。例如 INT 类型的数据允许隐式转换为 BIGINT 类型。额外注意的是:按照类型层次结构允许将 STRING 类型隐式转换为 DOUBLE 类型。
3.3 复杂类型
| 类型 | 描述 | 示例 |
|---|---|---|
| STRUCT | 类似于对象,是字段的集合,字段的类型可以不同,可以使用 名称.字段名 方式进行访问 |
STRUCT (‘xiaoming’, 12 , ‘2018-12-12’) |
| MAP | 键值对的集合,可以使用 名称[key] 的方式访问对应的值 |
map(‘a’, 1, ‘b’, 2) |
| ARRAY | 数组是一组具有相同类型和名称的变量的集合,可以使用 名称[index] 访问对应的值 |
ARRAY(‘a’, ‘b’, ‘c’, ‘d’) |
3.4 示例
如下给出一个基本数据类型和复杂数据类型的使用示例:
1 | CREATE TABLE students( |
四、内容格式
当数据存储在文本文件中,必须按照一定格式区别行和列,如使用逗号作为分隔符的 CSV 文件 (Comma-Separated Values) 或者使用制表符作为分隔值的 TSV 文件 (Tab-Separated Values)。但此时也存在一个缺点,就是正常的文件内容中也可能出现逗号或者制表符。
所以 Hive 默认使用了几个平时很少出现的字符,这些字符一般不会作为内容出现在文件中。Hive 默认的行和列分隔符如下表所示。
| 分隔符 | 描述 |
|---|---|
| \n | 对于文本文件来说,每行是一条记录,所以可以使用换行符来分割记录 |
| ^A (Ctrl+A) | 分割字段 (列),在 CREATE TABLE 语句中也可以使用八进制编码 \001 来表示 |
| ^B | 用于分割 ARRAY 或者 STRUCT 中的元素,或者用于 MAP 中键值对之间的分割, 在 CREATE TABLE 语句中也可以使用八进制编码 \002 表示 |
| ^C | 用于 MAP 中键和值之间的分割,在 CREATE TABLE 语句中也可以使用八进制编码 \003 表示 |
使用示例如下:
1 | CREATE TABLE page_view(viewTime INT, userid BIGINT) |
五、存储格式
5.1 支持的存储格式
Hive 会在 HDFS 为每个数据库上创建一个目录,数据库中的表是该目录的子目录,表中的数据会以文件的形式存储在对应的表目录下。Hive 支持以下几种文件存储格式:
| 格式 | 说明 |
|---|---|
| TextFile | 存储为纯文本文件。 这是 Hive 默认的文件存储格式。这种存储方式数据不做压缩,磁盘开销大,数据解析开销大。 |
| SequenceFile | SequenceFile 是 Hadoop API 提供的一种二进制文件,它将数据以<key,value>的形式序列化到文件中。这种二进制文件内部使用 Hadoop 的标准的 Writable 接口实现序列化和反序列化。它与 Hadoop API 中的 MapFile 是互相兼容的。Hive 中的 SequenceFile 继承自 Hadoop API 的 SequenceFile,不过它的 key 为空,使用 value 存放实际的值,这样是为了避免 MR 在运行 map 阶段进行额外的排序操作。 |
| RCFile | RCFile 文件格式是 FaceBook 开源的一种 Hive 的文件存储格式,首先将表分为几个行组,对每个行组内的数据按列存储,每一列的数据都是分开存储。 |
| ORC Files | ORC 是在一定程度上扩展了 RCFile,是对 RCFile 的优化。 |
| Avro Files | Avro 是一个数据序列化系统,设计用于支持大批量数据交换的应用。它的主要特点有:支持二进制序列化方式,可以便捷,快速地处理大量数据;动态语言友好,Avro 提供的机制使动态语言可以方便地处理 Avro 数据。 |
| Parquet | Parquet 是基于 Dremel 的数据模型和算法实现的,面向分析型业务的列式存储格式。它通过按列进行高效压缩和特殊的编码技术,从而在降低存储空间的同时提高了 IO 效率。 |
以上压缩格式中 ORC 和 Parquet 的综合性能突出,使用较为广泛,推荐使用这两种格式。
5.2 指定存储格式
通常在创建表的时候使用 STORED AS 参数指定:
1 | CREATE TABLE page_view(viewTime INT, userid BIGINT) |
各个存储文件类型指定方式如下:
- STORED AS TEXTFILE
- STORED AS SEQUENCEFILE
- STORED AS ORC
- STORED AS PARQUET
- STORED AS AVRO
- STORED AS RCFILE
六、内部表和外部表
内部表又叫做管理表 (Managed/Internal Table),创建表时不做任何指定,默认创建的就是内部表。想要创建外部表 (External Table),则需要使用 External 进行修饰。 内部表和外部表主要区别如下:
| 内部表 | 外部表 | |
|---|---|---|
| 数据存储位置 | 内部表数据存储的位置由 hive.metastore.warehouse.dir 参数指定,默认情况下表的数据存储在 HDFS 的 /user/hive/warehouse/数据库名.db/表名/ 目录下 |
外部表数据的存储位置创建表时由 Location 参数指定; |
| 导入数据 | 在导入数据到内部表,内部表将数据移动到自己的数据仓库目录下,数据的生命周期由 Hive 来进行管理 | 外部表不会将数据移动到自己的数据仓库目录下,只是在元数据中存储了数据的位置 |
| 删除表 | 删除元数据(metadata)和文件 | 只删除元数据(metadata) |
参考资料
- Hive Getting Started
- Hive SQL 的编译过程
- LanguageManual DDL
- LanguageManual Types
- Managed vs. External Tables
Linux环境下Hive的安装
一、安装Hive
1.1 下载并解压
下载所需版本的 Hive,这里我下载版本为 cdh5.15.2。下载地址:http://archive.cloudera.com/cdh5/cdh/5/ (这个地址的cloudera要付费用户才有下载权限,可用:http://hive.apache.org/downloads.html)
1 | 下载后进行解压 |
1.2 配置环境变量
1 | vim /etc/profile |
添加环境变量:
1 | export HIVE_HOME=/usr/app/hive-1.1.0-cdh5.15.2 |
使得配置的环境变量立即生效:
1 | source /etc/profile |
1.3 修改配置
1. hive-env.sh
进入安装目录下的 conf/ 目录,拷贝 Hive 的环境配置模板 hive-env.sh.template
1 | cp hive-env.sh.template hive-env.sh |
修改 hive-env.sh,指定 Hadoop 的安装路径:
1 | HADOOP_HOME=/usr/app/hadoop-2.6.0-cdh5.15.2 |
2. hive-site.xml
新建 hive-site.xml 文件,内容如下,主要是配置存放元数据的 MySQL 的地址、驱动、用户名和密码等信息:
1 |
|
1.4 拷贝数据库驱动
使用了hive为什么要加mysql? :“因为Hive默认的metadata(元数据)是存储在内嵌的derby数据库里面的,但是有一个弊端就是同一时间只能有一个Hive实例访问,这适合做开发程序时做本地测试。Hive提供了增强配置,可将数据库替换成mysql等关系型数据库,将存储数据独立出来在多个服务示例之间共享。由此可见,你在哪路径下,执行hive指令,就在哪路径下生成metastore_db。建一套数据库文件,这样是极其不合适的,公司里每个人若不一样,则会显得非常混杂。导致员工之间无法公用交流。为此,需公用的,mysql。”
将 MySQL 驱动包拷贝到 Hive 安装目录的 lib 目录下, MySQL 驱动的下载地址为:https://dev.mysql.com/downloads/connector/j/ , 在本仓库的resources 目录下我也上传了一份,有需要的可以自行下载。

1.5 初始化元数据库
当使用的 hive 是 1.x 版本时,可以不进行初始化操作,Hive 会在第一次启动的时候会自动进行初始化,但不会生成所有的元数据信息表,只会初始化必要的一部分,在之后的使用中用到其余表时会自动创建;
当使用的 hive 是 2.x 版本时,必须手动初始化元数据库。初始化命令:
1
2schematool 命令在安装目录的 bin 目录下,由于上面已经配置过环境变量,在任意位置执行即可
schematool -dbType mysql -initSchema
这里我使用的是 CDH 的 hive-1.1.0-cdh5.15.2.tar.gz,对应 Hive 1.1.0 版本,可以跳过这一步。
1.6 启动
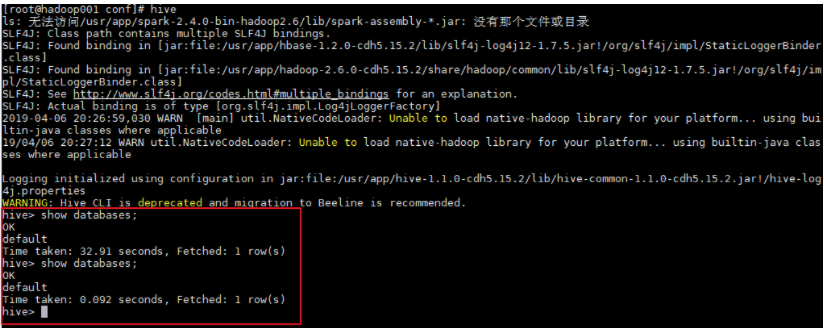
由于已经将 Hive 的 bin 目录配置到环境变量,直接使用以下命令启动,成功进入交互式命令行后执行 show databases 命令,无异常则代表搭建成功。
1 | 需要先启动Hadoop和MySQL |
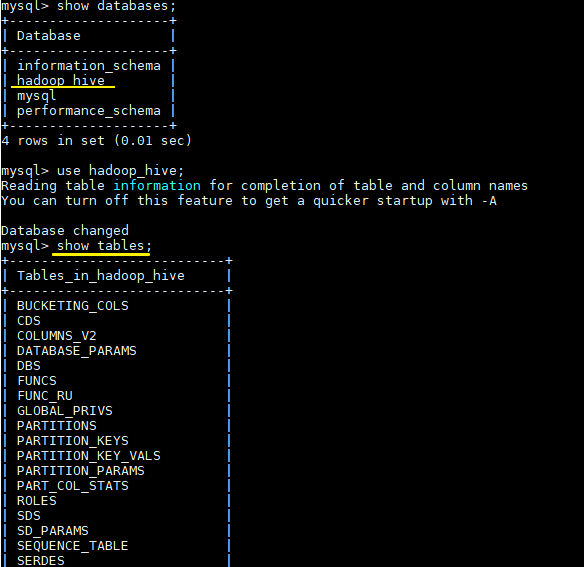
在 Mysql 中也能看到 Hive 创建的库和存放元数据信息的表
二、HiveServer2/beeline
Hive 内置了 HiveServer 和 HiveServer2 服务,两者都允许客户端使用多种编程语言进行连接,但是 HiveServer 不能处理多个客户端的并发请求,因此产生了 HiveServer2。HiveServer2(HS2)允许远程客户端可以使用各种编程语言向 Hive 提交请求并检索结果,支持多客户端并发访问和身份验证。HS2 是由多个服务组成的单个进程,其包括基于 Thrift 的 Hive 服务(TCP 或 HTTP)和用于 Web UI 的 Jetty Web 服务。
HiveServer2 拥有自己的 CLI 工具——Beeline。Beeline 是一个基于 SQLLine 的 JDBC 客户端。由于目前 HiveServer2 是 Hive 开发维护的重点,所以官方更加推荐使用 Beeline 而不是 Hive CLI。以下主要讲解 Beeline 的配置方式。
2.1 修改Hadoop配置
修改 hadoop 集群的 core-site.xml 配置文件,增加如下配置,指定 hadoop 的 root 用户可以代理本机上所有的用户。
1 | <property> |
之所以要配置这一步,是因为 hadoop 2.0 以后引入了安全伪装机制,使得 hadoop 不允许上层系统(如 hive)直接将实际用户传递到 hadoop 层,而应该将实际用户传递给一个超级代理,由该代理在 hadoop 上执行操作,以避免任意客户端随意操作 hadoop。如果不配置这一步,在之后的连接中可能会抛出 AuthorizationException 异常。
关于 Hadoop 的用户代理机制,可以参考:hadoop 的用户代理机制 或 Superusers Acting On Behalf Of Other Users
2.2 启动hiveserver2
由于上面已经配置过环境变量,这里直接启动即可:
1 | nohup hiveserver2 & |
2.3 使用beeline
可以使用以下命令进入 beeline 交互式命令行,出现 Connected 则代表连接成功。
1 | beeline -u jdbc:hive2://hadoop001:10000 -n root |
注意:Hadoop用root用户启动。启动流程:MySQL & Hadoop -> HiveServer2 -> beeline交互式命令行。
Hive CLI和Beeline命令行的基本使用
一、Hive CLI
1.1 Help
使用 hive -H 或者 hive --help 命令可以查看所有命令的帮助,显示如下:
1 | usage: hive |
1.2 交互式命令行
直接使用 Hive 命令,不加任何参数,即可进入交互式命令行。
1.3 执行SQL命令
在不进入交互式命令行的情况下,可以使用 hive -e 执行 SQL 命令。
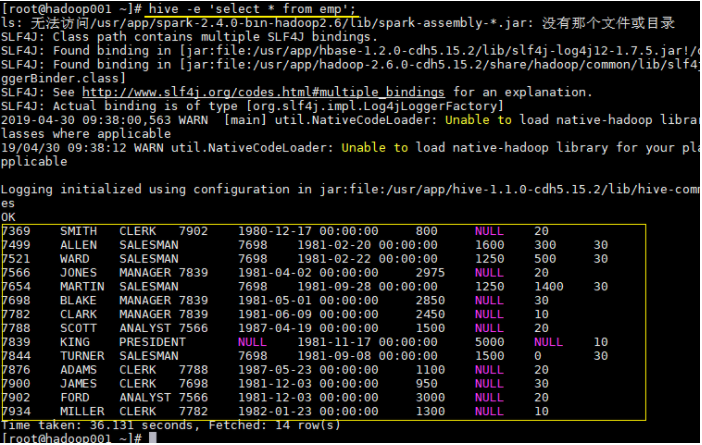
1 | hive -e 'select * from emp'; |
不知道有哪些数据库的时候可以执行:
1 | show databases; |
1.4 执行SQL脚本
用于执行的 sql 脚本可以在本地文件系统,也可以在 HDFS 上。
1 | 本地文件系统 |
不知道HDFS的访问端口的时候可以检查${HADOOP_HOME}/etc/hadoop/core-site.xml配置文件中的配置参数:fs.default.name namenode,默认8020。该参数为namenode RPC交互端口。
其中 simple.sql 内容如下:
1 | select * from emp; |
1.5 配置Hive变量
可以使用 --hiveconf 设置 Hive 运行时的变量。
1 | hive -e 'select * from emp' \ |
hive.exec.scratchdir:指定 HDFS 上目录位置,用于存储不同 map/reduce 阶段的执行计划和这些阶段的中间输出结果。
1.6 配置文件启动
使用 -i 可以在进入交互模式之前运行初始化脚本,相当于指定配置文件启动。
1 | hive -i /usr/file/hive-init.conf; |
其中 hive-init.conf 的内容如下:
1 | set hive.exec.mode.local.auto = true; |
hive.exec.mode.local.auto 默认值为 false,这里设置为 true ,代表开启本地模式。
1.7 用户自定义变量
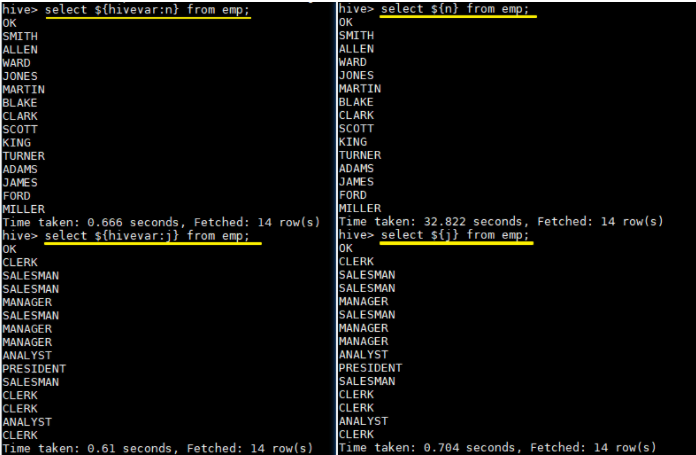
--define <key=value> 和 --hivevar <key=value> 在功能上是等价的,都是用来实现自定义变量,这里给出一个示例:
定义变量:
1 | hive --define n=ename --hiveconf --hivevar j=job; |
在查询中引用自定义变量:
1 | # 以下两条语句等价 |
结果如下:
二、Beeline
2.1 HiveServer2
Hive 内置了 HiveServer 和 HiveServer2 服务,两者都允许客户端使用多种编程语言进行连接,但是 HiveServer 不能处理多个客户端的并发请求,所以产生了 HiveServer2。
HiveServer2(HS2)允许远程客户端可以使用各种编程语言向 Hive 提交请求并检索结果,支持多客户端并发访问和身份验证。HS2 是由多个服务组成的单个进程,其包括基于 Thrift 的 Hive 服务(TCP 或 HTTP)和用于 Web UI 的 Jetty Web 服务器。
HiveServer2 拥有自己的 CLI(Beeline),Beeline 是一个基于 SQLLine 的 JDBC 客户端。由于 HiveServer2 是 Hive 开发维护的重点 (Hive0.15 后就不再支持 hiveserver),所以 Hive CLI 已经不推荐使用了,官方更加推荐使用 Beeline。
2.1 Beeline
Beeline 拥有更多可使用参数,可以使用 beeline --help 查看,完整参数如下:
1 | Usage: java org.apache.hive.cli.beeline.BeeLine |
2.3 常用参数
在 Hive CLI 中支持的参数,Beeline 都支持,常用的参数如下。更多参数说明可以参见官方文档 Beeline Command Options
| 参数 | 说明 |
|---|---|
| -u <database URL> | 数据库地址 |
| -n <username> | 用户名 |
| -p <password> | 密码 |
| -d <driver class> | 驱动 (可选) |
| -e <query> | 执行 SQL 命令 |
| -f <file> | 执行 SQL 脚本 |
| -i (or)–init <file or files> | 在进入交互模式之前运行初始化脚本 |
| –property-file <file> | 指定配置文件 |
| –hiveconf property*=*value | 指定配置属性 |
| –hivevar name*=*value | 用户自定义属性,在会话级别有效 |
示例: 使用用户名和密码连接 Hive
1 | beeline -u jdbc:hive2://localhost:10000 -n username -p password |
三、Hive配置
可以通过三种方式对 Hive 的相关属性进行配置,分别介绍如下:
3.1 配置文件
方式一为使用配置文件,使用配置文件指定的配置是永久有效的。Hive 有以下三个可选的配置文件:
hive-site.xml :Hive 的主要配置文件;
hivemetastore-site.xml: 关于元数据的配置;
hiveserver2-site.xml:关于 HiveServer2 的配置。
示例如下,在 hive-site.xml 配置 hive.exec.scratchdir:
1 | <property> |
3.2 hiveconf
方式二为在启动命令行 (Hive CLI / Beeline) 的时候使用 --hiveconf 指定配置,这种方式指定的配置作用于整个 Session。
1 | hive --hiveconf hive.exec.scratchdir=/tmp/mydir |
3.3 set
方式三为在交互式环境下 (Hive CLI / Beeline),使用 set 命令指定。这种设置的作用范围也是 Session 级别的,配置对于执行该命令后的所有命令生效。set 兼具设置参数和查看参数的功能。如下:
1 | 0: jdbc:hive2://hadoop001:10000> set hive.exec.scratchdir=/tmp/mydir; |
3.4 配置优先级
配置的优先顺序如下 (由低到高):hive-site.xml - >hivemetastore-site.xml- > hiveserver2-site.xml - > -- hiveconf- > set
3.5 配置参数
Hive 可选的配置参数非常多,在用到时查阅官方文档即可AdminManual Configuration
参考资料
Hive常用DDL操作
一、Database
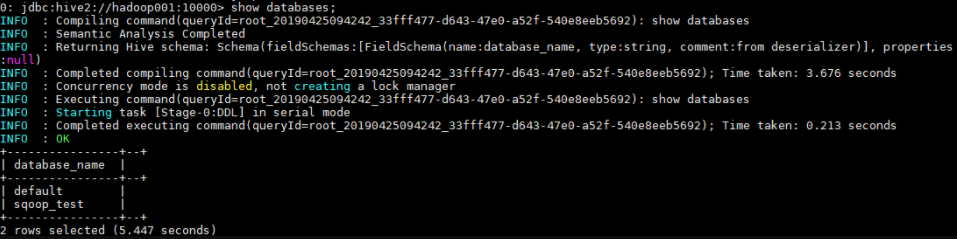
1.1 查看数据列表
1 | show databases; |
1.2 使用数据库
1 | USE database_name; |
1.3 新建数据库
语法:
1 | CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name --DATABASE|SCHEMA 是等价的 |
示例:
1 | CREATE DATABASE IF NOT EXISTS hive_test |
1.4 查看数据库信息
语法:
1 | DESC DATABASE [EXTENDED] db_name; --EXTENDED 表示是否显示额外属性 |
示例:
1 | DESC DATABASE EXTENDED hive_test; |
1.5 删除数据库
语法:
1 | DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE]; |
- 默认行为是 RESTRICT,如果数据库中存在表则删除失败。要想删除库及其中的表,可以使用 CASCADE 级联删除。
示例:
1 | DROP DATABASE IF EXISTS hive_test CASCADE; |
二、创建表
2.1 建表语法
1 | CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name --表名 |
2.2 内部表
1 | CREATE TABLE emp( |
2.3 外部表
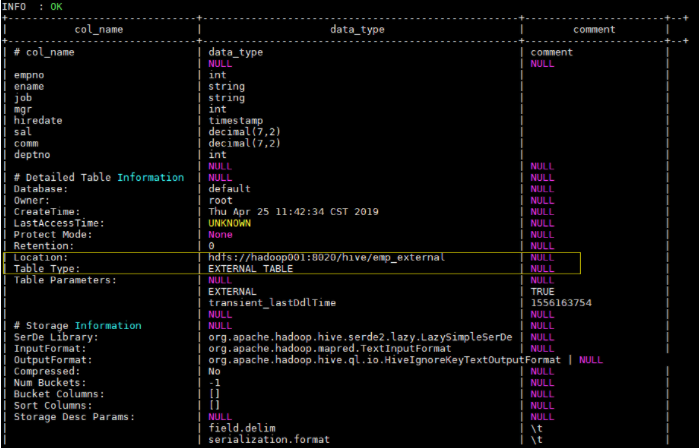
1 | CREATE EXTERNAL TABLE emp_external( |
使用 desc formatted emp_external(FORMATTED 以友好的展现方式查看表详情) desc extended emp_external;(EXTENDED 是否显示额外属性) 命令可以查看表的详细信息如下:
2.4 分区表
Hive分区:是指按照数据表的某列或某些列分为多个区,区从形式上可以理解为文件夹,比如我们要收集某个大型网站的日志数据,一个网站每天的日志数据存在同一张表上,由于每天会生成大量的日志,导致数据表的内容巨大,在查询时进行全表扫描耗费的资源非常多。那其实这个情况下,我们可以按照日期对数据表进行分区,不同日期的数据存放在不同的分区,在查询时只要指定分区字段的值就可以直接从该分区查找。
1 | CREATE EXTERNAL TABLE emp_partition( |
2.5 分桶表
分桶:分桶是相对分区进行更细粒度的划分。分桶将整个数据内容安装某列属性值得hash值进行区分,如要安装name属性分为3个桶,就是对name属性值的hash值对3取摸,按照取模结果对数据分桶。如取模结果为0的数据记录存放到一个文件,取模为1的数据存放到一个文件,取模为2的数据存放到一个文件。
1 | CREATE EXTERNAL TABLE emp_bucket( |
2.6 倾斜表
通过指定一个或者多个列经常出现的值(严重偏斜),Hive 会自动将涉及到这些值的数据拆分为单独的文件。在查询时,如果涉及到倾斜值,它就直接从独立文件中获取数据,而不是扫描所有文件,这使得性能得到提升。
1 | CREATE EXTERNAL TABLE emp_skewed( |
2.7 临时表
临时表仅对当前 session 可见,临时表的数据将存储在用户的暂存目录中,并在会话结束后删除。如果临时表与永久表表名相同,则对该表名的任何引用都将解析为临时表,而不是永久表。临时表还具有以下两个限制:
- 不支持分区列;
- 不支持创建索引。
1 | CREATE TEMPORARY TABLE emp_temp( |
2.8 CTAS创建表
支持从查询语句的结果创建表:
1 | CREATE TABLE emp_copy AS SELECT * FROM emp WHERE deptno='20'; |
2.9 复制表结构
语法:
1 | CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name --创建表表名 |
示例:
1 | CREATE TEMPORARY EXTERNAL TABLE IF NOT EXISTS emp_co LIKE emp |
2.10 加载数据到表
加载数据到表中属于 DML 操作,这里为了方便大家测试,先简单介绍一下加载本地数据到表中:
1 | -- 加载数据到 emp 表中 |
其中 emp.txt 的内容如下,你可以直接复制使用,也可以到本仓库的resources 目录下载:
1 | 7369 SMITH CLERK 7902 1980-12-17 00:00:00 800.00 20 |
加载后可查询表中数据:
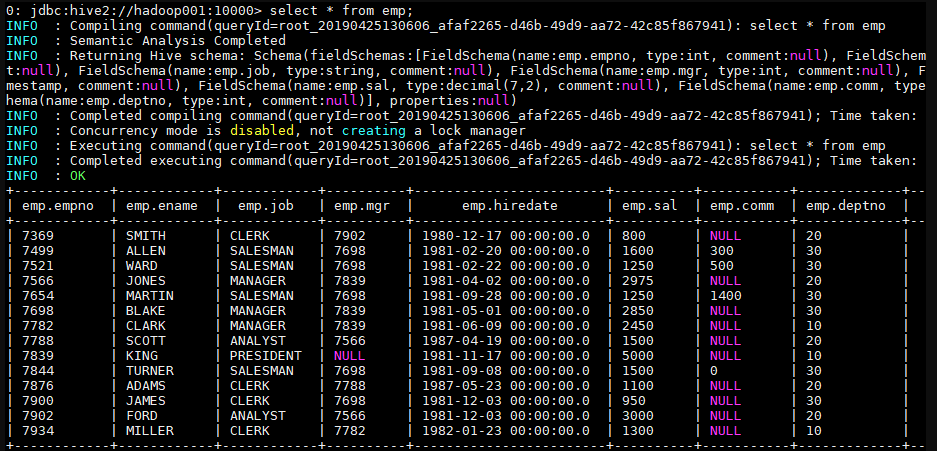
三、修改表
3.1 重命名表
语法:
1 | ALTER TABLE table_name RENAME TO new_table_name; |
示例:
1 | ALTER TABLE emp_temp RENAME TO new_emp; --把 emp_temp 表重命名为 new_emp |
3.2 修改列
语法:
1 | ALTER TABLE table_name [PARTITION partition_spec] CHANGE [COLUMN] col_old_name col_new_name column_type |
示例:
1 | -- 修改字段名和类型 |
3.3 新增列
示例:
1 | ALTER TABLE emp_temp ADD COLUMNS (address STRING COMMENT 'home address'); |
四、清空表/删除表
4.1 清空表
语法:
1 | -- 清空整个表或表指定分区中的数据 |
- 目前只有内部表才能执行 TRUNCATE 操作,外部表执行时会抛出异常
Cannot truncate non-managed table XXXX。
示例:
1 | TRUNCATE TABLE emp_mgt_ptn PARTITION (deptno=20); |
4.2 删除表
语法:
1 | DROP TABLE [IF EXISTS] table_name [PURGE]; |
- 内部表:不仅会删除表的元数据,同时会删除 HDFS 上的数据;
- 外部表:只会删除表的元数据,不会删除 HDFS 上的数据;
- 删除视图引用的表时,不会给出警告(但视图已经无效了,必须由用户删除或重新创建)。
五、其他命令
5.1 Describe
查看数据库:
1 | DESCRIBE|Desc DATABASE [EXTENDED] db_name; --EXTENDED 是否显示额外属性 |
查看表:
1 | DESCRIBE|Desc [EXTENDED|FORMATTED] table_name --FORMATTED 以友好的展现方式查看表详情 |
5.2 Show
1. 查看数据库列表
1 | -- 语法 |
LIKE 子句允许使用正则表达式进行过滤,但是 SHOW 语句当中的 LIKE 子句只支持 *(通配符)和 |(条件或)两个符号。例如 employees,emp *,emp * | * ees,所有这些都将匹配名为 employees 的数据库。
2. 查看表的列表
1 | -- 语法 |
3. 查看视图列表
1 | SHOW VIEWS [IN/FROM database_name] [LIKE 'pattern_with_wildcards']; --仅支持 Hive 2.2.0 + |
4. 查看表的分区列表
1 | SHOW PARTITIONS table_name; |
5. 查看表/视图的创建语句
1 | SHOW CREATE TABLE ([db_name.]table_name|view_name); |
参考资料
Hive分区表和分桶表
一、分区表
1.1 概念
Hive 中的表对应为 HDFS 上的指定目录,在查询数据时候,默认会对全表进行扫描,这样时间和性能的消耗都非常大。
分区为 HDFS 上表目录的子目录,数据按照分区存储在子目录中。如果查询的 where 字句的中包含分区条件,则直接从该分区去查找,而不是扫描整个表目录,合理的分区设计可以极大提高查询速度和性能。
这里说明一下分区表并 Hive 独有的概念,实际上这个概念非常常见。比如在我们常用的 Oracle 数据库中,当表中的数据量不断增大,查询数据的速度就会下降,这时也可以对表进行分区。表进行分区后,逻辑上表仍然是一张完整的表,只是将表中的数据存放到多个表空间(物理文件上),这样查询数据时,就不必要每次都扫描整张表,从而提升查询性能。
1.2 使用场景
通常,在管理大规模数据集的时候都需要进行分区,比如将日志文件按天进行分区,从而保证数据细粒度的划分,使得查询性能得到提升。
1.3 创建分区表
在 Hive 中可以使用 PARTITIONED BY 子句创建分区表。表可以包含一个或多个分区列,程序会为分区列中的每个不同值组合创建单独的数据目录。下面的我们创建一张雇员表作为测试:
1 | CREATE EXTERNAL TABLE emp_partition( |
1.4 加载数据到分区表
加载数据到分区表时候必须要指定数据所处的分区:
1 | 加载部门编号为20的数据到表中 |
1.5 查看分区目录
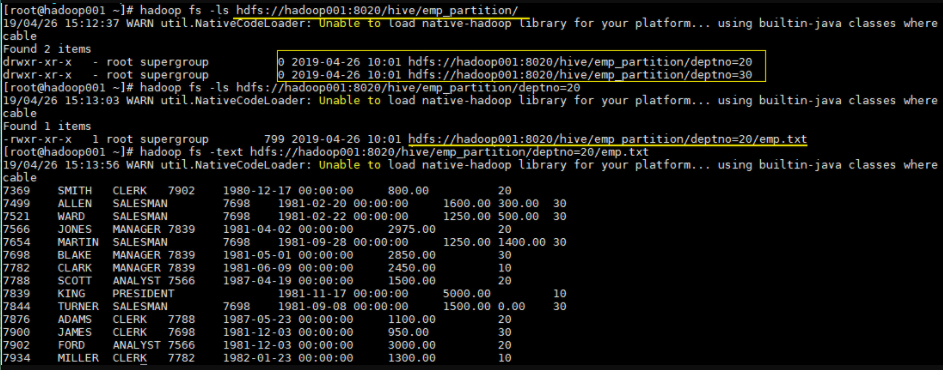
这时候我们直接查看表目录,可以看到表目录下存在两个子目录,分别是 deptno=20 和 deptno=30,这就是分区目录,分区目录下才是我们加载的数据文件。
1 | hadoop fs -ls hdfs://hadoop001:8020/hive/emp_partition/ |
这时候当你的查询语句的 where 包含 deptno=20,则就去对应的分区目录下进行查找,而不用扫描全表。
二、分桶表
1.1 简介
分区提供了一个隔离数据和优化查询的可行方案,但是并非所有的数据集都可以形成合理的分区,分区的数量也不是越多越好,过多的分区条件可能会导致很多分区上没有数据。同时 Hive 会限制动态分区可以创建的最大分区数,用来避免过多分区文件对文件系统产生负担。鉴于以上原因,Hive 还提供了一种更加细粒度的数据拆分方案:分桶表 (bucket Table)。
分桶表会将指定列的值进行哈希散列,并对 bucket(桶数量)取余,然后存储到对应的 bucket(桶)中。
1.2 理解分桶表
单从概念上理解分桶表可能会比较晦涩,其实和分区一样,分桶这个概念同样不是 Hive 独有的,对于 Java 开发人员而言,这可能是一个每天都会用到的概念,因为 Hive 中的分桶概念和 Java 数据结构中的 HashMap 的分桶概念是一致的。
当调用 HashMap 的 put() 方法存储数据时,程序会先对 key 值调用 hashCode() 方法计算出 hashcode,然后对数组长度取模计算出 index,最后将数据存储在数组 index 位置的链表上,链表达到一定阈值后会转换为红黑树 (JDK1.8+)。下图为 HashMap 的数据结构图:
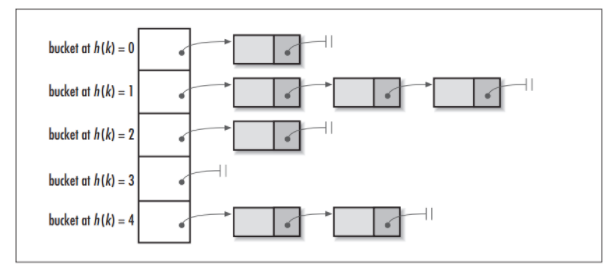
图片引用自:HashMap vs. Hashtable
1.3 创建分桶表
在 Hive 中,我们可以通过 CLUSTERED BY 指定分桶列,并通过 SORTED BY 指定桶中数据的排序参考列。下面为分桶表建表语句示例:
1 | CREATE EXTERNAL TABLE emp_bucket( |
1.4 加载数据到分桶表
这里直接使用 Load 语句向分桶表加载数据,数据时可以加载成功的,但是数据并不会分桶。
这是由于分桶的实质是对指定字段做了 hash 散列然后存放到对应文件中,这意味着向分桶表中插入数据是必然要通过 MapReduce,且 Reducer 的数量必须等于分桶的数量。由于以上原因,分桶表的数据通常只能使用 CTAS(CREATE TABLE AS SELECT) 方式插入,因为 CTAS 操作会触发 MapReduce。加载数据步骤如下:
1. 设置强制分桶
1 | set hive.enforce.bucketing = true; --Hive 2.x 不需要这一步 |
在 Hive 0.x and 1.x 版本,必须使用设置 hive.enforce.bucketing = true,表示强制分桶,允许程序根据表结构自动选择正确数量的 Reducer 和 cluster by column 来进行分桶。
2. CTAS导入数据
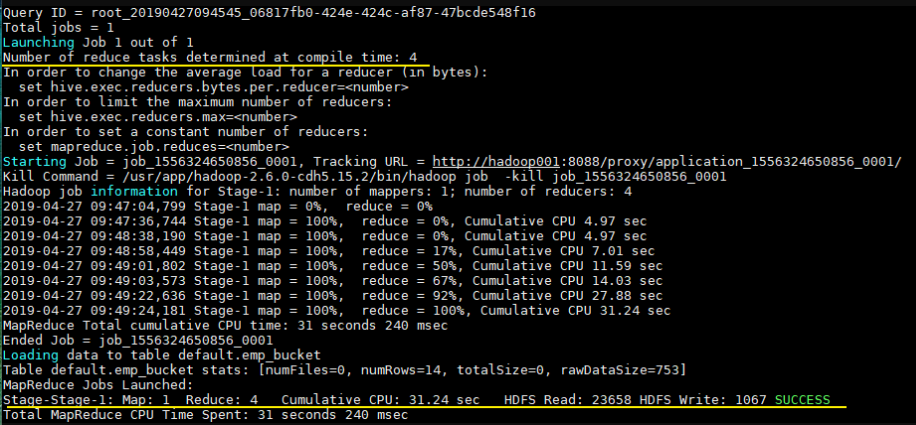
1 | INSERT INTO TABLE emp_bucket SELECT * FROM emp; --这里的 emp 表就是一张普通的雇员表 |
可以从执行日志看到 CTAS 触发 MapReduce 操作,且 Reducer 数量和建表时候指定 bucket 数量一致:
1.5 查看分桶文件
bucket(桶) 本质上就是表目录下的具体文件:
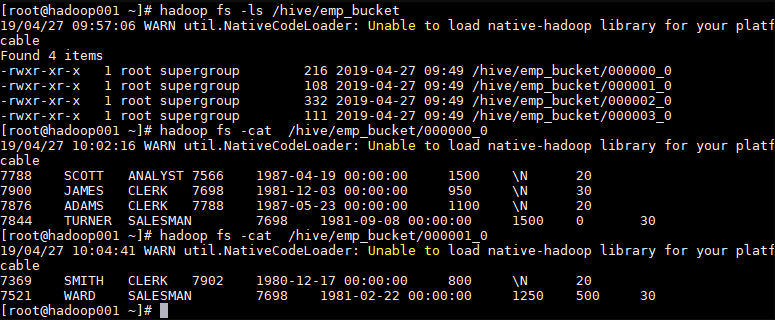
三、分区表和分桶表结合使用
分区表和分桶表的本质都是将数据按照不同粒度进行拆分,从而使得在查询时候不必扫描全表,只需要扫描对应的分区或分桶,从而提升查询效率。两者可以结合起来使用,从而保证表数据在不同粒度上都能得到合理的拆分。下面是 Hive 官方给出的示例:
1 | CREATE TABLE page_view_bucketed( |
此时导入数据时需要指定分区:
1 | INSERT OVERWRITE page_view_bucketed |
参考资料
Hive 视图和索引
一、视图
1.1 简介
Hive 中的视图和 RDBMS 中视图的概念一致,都是一组数据的逻辑表示,本质上就是一条 SELECT 语句的结果集。视图是纯粹的逻辑对象,没有关联的存储 (Hive 3.0.0 引入的物化视图除外),当查询引用视图时,Hive 可以将视图的定义与查询结合起来,例如将查询中的过滤器推送到视图中。
1.2 创建视图
1 | CREATE VIEW [IF NOT EXISTS] [db_name.]view_name -- 视图名称 |
在 Hive 中可以使用 CREATE VIEW 创建视图,如果已存在具有相同名称的表或视图,则会抛出异常,建议使用 IF NOT EXISTS 预做判断。在使用视图时候需要注意以下事项:
视图是只读的,不能用作 LOAD / INSERT / ALTER 的目标;
在创建视图时候视图就已经固定,对基表的后续更改(如添加列)将不会反映在视图;
删除基表并不会删除视图,需要手动删除视图;
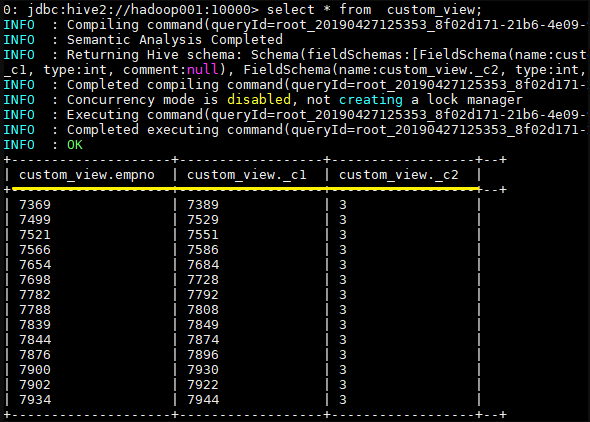
视图可能包含 ORDER BY 和 LIMIT 子句。如果引用视图的查询语句也包含这类子句,其执行优先级低于视图对应字句。例如,视图
custom_view指定 LIMIT 5,查询语句为select * from custom_view LIMIT 10,此时结果最多返回 5 行。创建视图时,如果未提供列名,则将从 SELECT 语句中自动派生列名;
创建视图时,如果 SELECT 语句中包含其他表达式,例如 x + y,则列名称将以_C0,_C1 等形式生成;
1
CREATE VIEW IF NOT EXISTS custom_view AS SELECT empno, empno+deptno , 1+2 FROM emp;
1.3 查看视图
1 | -- 查看所有视图: 没有单独查看视图列表的语句,只能使用 show tables |
1.4 删除视图
1 | DROP VIEW [IF EXISTS] [db_name.]view_name; |
删除视图时,如果被删除的视图被其他视图所引用,这时候程序不会发出警告,但是引用该视图其他视图已经失效,需要进行重建或者删除。
1.5 修改视图
1 | ALTER VIEW [db_name.]view_name AS select_statement; |
被更改的视图必须存在,且视图不能具有分区,如果视图具有分区,则修改失败。
1.6 修改视图属性
语法:
1 | ALTER VIEW [db_name.]view_name SET TBLPROPERTIES table_properties; |
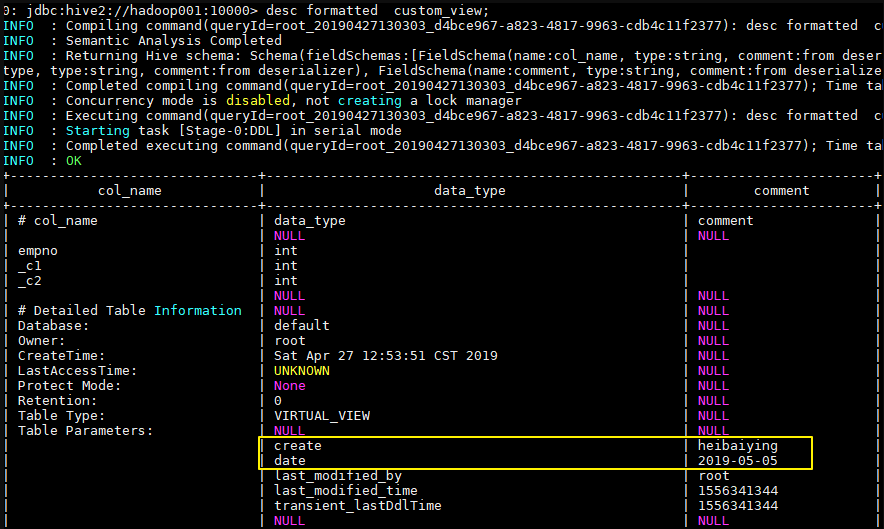
示例:
1 | ALTER VIEW custom_view SET TBLPROPERTIES ('create'='heibaiying','date'='2019-05-05'); |
二、索引
2.1 简介
Hive 在 0.7.0 引入了索引的功能,索引的设计目标是提高表某些列的查询速度。如果没有索引,带有谓词的查询(如’WHERE table1.column = 10’)会加载整个表或分区并处理所有行。但是如果 column 存在索引,则只需要加载和处理文件的一部分。
2.2 索引原理
在指定列上建立索引,会产生一张索引表(表结构如下),里面的字段包括:索引列的值、该值对应的 HDFS 文件路径、该值在文件中的偏移量。在查询涉及到索引字段时,首先到索引表查找索引列值对应的 HDFS 文件路径及偏移量,这样就避免了全表扫描。
1 | +--------------+----------------+----------+--+ |
2.3 创建索引
1 | CREATE INDEX index_name --索引名称 |
2.4 查看索引
1 | --显示表上所有列的索引 |
2.4 删除索引
删除索引会删除对应的索引表。
1 | DROP INDEX [IF EXISTS] index_name ON table_name; |
如果存在索引的表被删除了,其对应的索引和索引表都会被删除。如果被索引表的某个分区被删除了,那么分区对应的分区索引也会被删除。
2.5 重建索引
1 | ALTER INDEX index_name ON table_name [PARTITION partition_spec] REBUILD; |
重建索引。如果指定了 PARTITION,则仅重建该分区的索引。
三、索引案例
3.1 创建索引
在 emp 表上针对 empno 字段创建名为 emp_index,索引数据存储在 emp_index_table 索引表中
1 | create index emp_index on table emp(empno) as |
此时索引表中是没有数据的,需要重建索引才会有索引的数据。
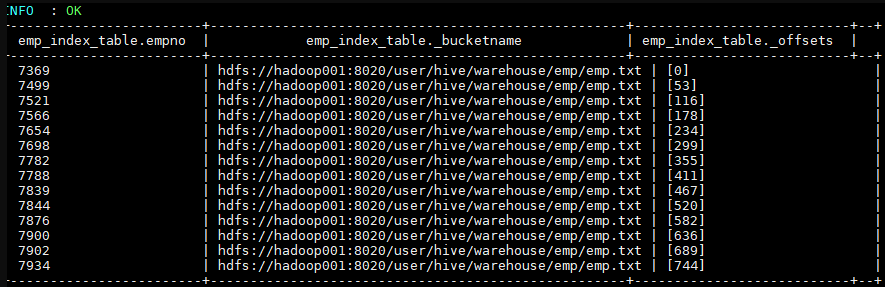
3.2 重建索引
1 | alter index emp_index on emp rebuild; |
Hive 会启动 MapReduce 作业去建立索引,建立好后查看索引表数据如下。三个表字段分别代表:索引列的值、该值对应的 HDFS 文件路径、该值在文件中的偏移量。
3.3 自动使用索引
默认情况下,虽然建立了索引,但是 Hive 在查询时候是不会自动去使用索引的,需要开启相关配置。开启配置后,涉及到索引列的查询就会使用索引功能去优化查询。
1 | SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat; |
3.4 查看索引
1 | SHOW INDEX ON emp; |

四、索引的缺陷
索引表最主要的一个缺陷在于:索引表无法自动 rebuild,这也就意味着如果表中有数据新增或删除,则必须手动 rebuild,重新执行 MapReduce 作业,生成索引表数据。
同时按照官方文档 的说明,Hive 会从 3.0 开始移除索引功能,主要基于以下两个原因:
- 具有自动重写的物化视图 (Materialized View) 可以产生与索引相似的效果(Hive 2.3.0 增加了对物化视图的支持,在 3.0 之后正式引入)。
- 使用列式存储文件格式(Parquet,ORC)进行存储时,这些格式支持选择性扫描,可以跳过不需要的文件或块。
ORC 内置的索引功能可以参阅这篇文章:Hive 性能优化之 ORC 索引–Row Group Index vs Bloom Filter Index
参考资料
Hive 常用DML操作
一、加载文件数据到表
1.1 语法
1 | LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] |
LOCAL关键字代表从本地文件系统加载文件,省略则代表从 HDFS 上加载文件:
- 从本地文件系统加载文件时,
filepath可以是绝对路径也可以是相对路径 (建议使用绝对路径); - 从 HDFS 加载文件时候,
filepath为文件完整的 URL 地址:如hdfs://namenode:port/user/hive/project/ data1
filepath可以是文件路径 (在这种情况下 Hive 会将文件移动到表中),也可以目录路径 (在这种情况下,Hive 会将该目录中的所有文件移动到表中);如果使用 OVERWRITE 关键字,则将删除目标表(或分区)的内容,使用新的数据填充;不使用此关键字,则数据以追加的方式加入;
加载的目标可以是表或分区。如果是分区表,则必须指定加载数据的分区;
加载文件的格式必须与建表时使用
STORED AS指定的存储格式相同。
使用建议:
不论是本地路径还是 URL 都建议使用完整的。虽然可以使用不完整的 URL 地址,此时 Hive 将使用 hadoop 中的 fs.default.name 配置来推断地址,但是为避免不必要的错误,建议使用完整的本地路径或 URL 地址;
加载对象是分区表时建议显示指定分区。在 Hive 3.0 之后,内部将加载 (LOAD) 重写为 INSERT AS SELECT,此时如果不指定分区,INSERT AS SELECT 将假设最后一组列是分区列,如果该列不是表定义的分区,它将抛出错误。为避免错误,还是建议显示指定分区。
1.2 示例
新建分区表:
1 | CREATE TABLE emp_ptn( |
从 HDFS 上加载数据到分区表:
1 | LOAD DATA INPATH "hdfs://hadoop001:8020/mydir/emp.txt" OVERWRITE INTO TABLE emp_ptn PARTITION (deptno=20); |
emp.txt 文件可在本仓库的 resources 目录中下载
加载后表中数据如下,分区列 deptno 全部赋值成 20:
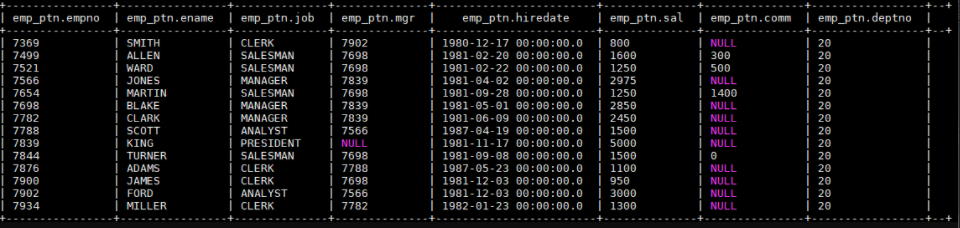
二、查询结果插入到表
2.1 语法
1 | INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] |
Hive 0.13.0 开始,建表时可以通过使用 TBLPROPERTIES(“immutable”=“true”)来创建不可变表 (immutable table) ,如果不可以变表中存在数据,则 INSERT INTO 失败。(注:INSERT OVERWRITE 的语句不受
immutable属性的影响);可以对表或分区执行插入操作。如果表已分区,则必须通过指定所有分区列的值来指定表的特定分区;
从 Hive 1.1.0 开始,TABLE 关键字是可选的;
从 Hive 1.2.0 开始 ,可以采用 INSERT INTO tablename(z,x,c1) 指明插入列;
可以将 SELECT 语句的查询结果插入多个表(或分区),称为多表插入。语法如下:
1
2
3
4
5FROM from_statement
INSERT OVERWRITE TABLE tablename1
[PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1
[INSERT OVERWRITE TABLE tablename2 [PARTITION ... [IF NOT EXISTS]] select_statement2]
[INSERT INTO TABLE tablename2 [PARTITION ...] select_statement2] ...;
2.2 动态插入分区
1 | INSERT OVERWRITE TABLE tablename PARTITION (partcol1[=val1], partcol2[=val2] ...) |
在向分区表插入数据时候,分区列名是必须的,但是列值是可选的。如果给出了分区列值,我们将其称为静态分区,否则它是动态分区。动态分区列必须在 SELECT 语句的列中最后指定,并且与它们在 PARTITION() 子句中出现的顺序相同。
注意:Hive 0.9.0 之前的版本动态分区插入是默认禁用的,而 0.9.0 之后的版本则默认启用。以下是动态分区的相关配置:
| 配置 | 默认值 | 说明 |
|---|---|---|
hive.exec.dynamic.partition |
true |
需要设置为 true 才能启用动态分区插入 |
hive.exec.dynamic.partition.mode |
strict |
在严格模式 (strict) 下,用户必须至少指定一个静态分区,以防用户意外覆盖所有分区,在非严格模式下,允许所有分区都是动态的 |
hive.exec.max.dynamic.partitions.pernode |
100 | 允许在每个 mapper/reducer 节点中创建的最大动态分区数 |
hive.exec.max.dynamic.partitions |
1000 | 允许总共创建的最大动态分区数 |
hive.exec.max.created.files |
100000 | 作业中所有 mapper/reducer 创建的 HDFS 文件的最大数量 |
hive.error.on.empty.partition |
false |
如果动态分区插入生成空结果,是否抛出异常 |
2.3 示例
- 新建 emp 表,作为查询对象表
1 | CREATE TABLE emp( |
完成后 emp 表中数据如下:
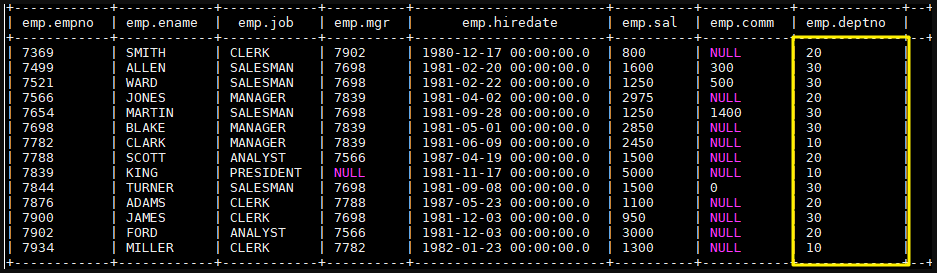
- 为清晰演示,先清空
emp_ptn表中加载的数据:
1 | TRUNCATE TABLE emp_ptn; |
- 静态分区演示:从
emp表中查询部门编号为 20 的员工数据,并插入emp_ptn表中,语句如下:
1 | INSERT OVERWRITE TABLE emp_ptn PARTITION (deptno=20) |
完成后 emp_ptn 表中数据如下:

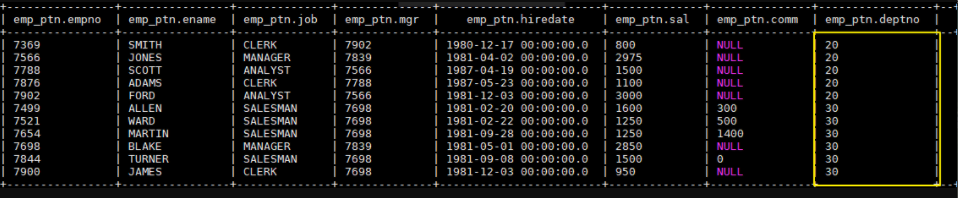
- 接着演示动态分区:
1 | -- 由于我们只有一个分区,且还是动态分区,所以需要关闭严格默认。因为在严格模式下,用户必须至少指定一个静态分区 |
完成后 emp_ptn 表中数据如下:
三、使用SQL语句插入值
1 | INSERT INTO TABLE tablename [PARTITION (partcol1[=val1], partcol2[=val2] ...)] |
- 使用时必须为表中的每个列都提供值。不支持只向部分列插入值(可以为缺省值的列提供空值来消除这个弊端);
- 如果目标表表支持 ACID 及其事务管理器,则插入后自动提交;
- 不支持支持复杂类型 (array, map, struct, union) 的插入。
四、更新和删除数据
4.1 语法
更新和删除的语法比较简单,和关系型数据库一致。需要注意的是这两个操作都只能在支持 ACID 的表,也就是事务表上才能执行。
1 | -- 更新 |
4.2 示例
1. 修改配置
首先需要更改 hive-site.xml,添加如下配置,开启事务支持,配置完成后需要重启 Hive 服务。
1 | <property> |
2. 创建测试表
创建用于测试的事务表,建表时候指定属性 transactional = true 则代表该表是事务表。需要注意的是,按照官方文档 的说明,目前 Hive 中的事务表有以下限制:
- 必须是 buckets Table;
- 仅支持 ORC 文件格式;
- 不支持 LOAD DATA …语句。
1 | CREATE TABLE emp_ts( |
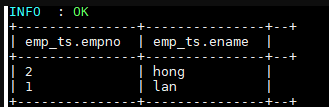
3. 插入测试数据
1 | INSERT INTO TABLE emp_ts VALUES (1,"ming"),(2,"hong"); |
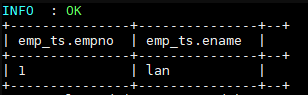
插入数据依靠的是 MapReduce 作业,执行成功后数据如下:
4. 测试更新和删除
1 | --更新数据 |
更新和删除数据依靠的也是 MapReduce 作业,执行成功后数据如下:
五、查询结果写出到文件系统
5.1 语法
1 | INSERT OVERWRITE [LOCAL] DIRECTORY directory1 |
OVERWRITE 关键字表示输出文件存在时,先删除后再重新写入;
和 Load 语句一样,建议无论是本地路径还是 URL 地址都使用完整的;
写入文件系统的数据被序列化为文本,其中列默认由^A 分隔,行由换行符分隔。如果列不是基本类型,则将其序列化为 JSON 格式。其中行分隔符不允许自定义,但列分隔符可以自定义,如下:
1
2
3
4
5
6
7-- 定义列分隔符为'\t'
insert overwrite local directory './test-04'
row format delimited
FIELDS TERMINATED BY '\t'
COLLECTION ITEMS TERMINATED BY ','
MAP KEYS TERMINATED BY ':'
select * from src;
5.2 示例
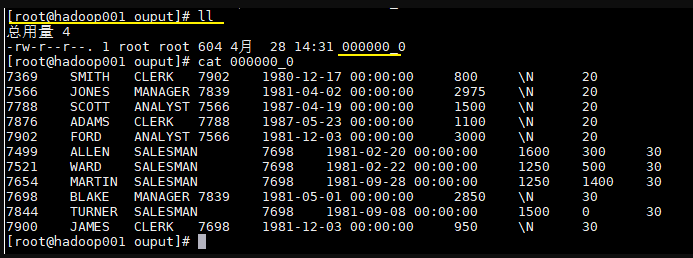
这里我们将上面创建的 emp_ptn 表导出到本地文件系统,语句如下:
1 | INSERT OVERWRITE LOCAL DIRECTORY '/usr/file/ouput' |
导出结果如下:
参考资料
Hive数据查询详解
一、数据准备
为了演示查询操作,这里需要预先创建三张表,并加载测试数据。
数据文件 emp.txt 和 dept.txt 可以从本仓库的resources 目录下载。
1.1 员工表
1 | -- 建表语句 |
1.2 部门表
1 | -- 建表语句 |
1.3 分区表
这里需要额外创建一张分区表,主要是为了演示分区查询:
1 | CREATE EXTERNAL TABLE emp_ptn( |
二、单表查询
2.1 SELECT
1 | -- 查询表中全部数据 |
2.2 WHERE
1 | -- 查询 10 号部门中员工编号大于 7782 的员工信息 |
2.3 DISTINCT
Hive 支持使用 DISTINCT 关键字去重。
1 | -- 查询所有工作类型 |
2.4 分区查询
分区查询 (Partition Based Queries),可以指定某个分区或者分区范围。
1 | -- 查询分区表中部门编号在[20,40]之间的员工 |
2.5 LIMIT
1 | -- 查询薪资最高的 5 名员工 |
2.6 GROUP BY
Hive 支持使用 GROUP BY 进行分组聚合操作。
1 | set hive.map.aggr=true; |
hive.map.aggr 控制程序如何进行聚合。默认值为 false。如果设置为 true,Hive 会在 map 阶段就执行一次聚合。这可以提高聚合效率,但需要消耗更多内存。
2.7 ORDER AND SORT
可以使用 ORDER BY 或者 Sort BY 对查询结果进行排序,排序字段可以是整型也可以是字符串:如果是整型,则按照大小排序;如果是字符串,则按照字典序排序。ORDER BY 和 SORT BY 的区别如下:
- 使用 ORDER BY 时会有一个 Reducer 对全部查询结果进行排序,可以保证数据的全局有序性;
- 使用 SORT BY 时只会在每个 Reducer 中进行排序,这可以保证每个 Reducer 的输出数据是有序的,但不能保证全局有序。
由于 ORDER BY 的时间可能很长,如果你设置了严格模式 (hive.mapred.mode = strict),则其后面必须再跟一个 limit 子句。
注 :hive.mapred.mode 默认值是 nonstrict ,也就是非严格模式。
1 | -- 查询员工工资,结果按照部门升序,按照工资降序排列 |
2.8 HAVING
可以使用 HAVING 对分组数据进行过滤。
1 | -- 查询工资总和大于 9000 的所有部门 |
2.9 DISTRIBUTE BY
如果想要把具有相同 Key 值的数据分发到同一个 Reducer 进行处理,这可以使用 DISTRIBUTE BY 字句。需要注意的是,DISTRIBUTE BY 虽然能把具有相同 Key 值的数据分发到同一个 Reducer,但是不能保证数据在 Reducer 上是有序的。情况如下:
把以下 5 个数据发送到两个 Reducer 上进行处理:
1 | k1 |
Reducer1 得到如下乱序数据:
1 | k1 |
Reducer2 得到数据如下:
1 | k4 |
如果想让 Reducer 上的数据是有序的,可以结合 SORT BY 使用 (示例如下),或者使用下面我们将要介绍的 CLUSTER BY。
1 | -- 将数据按照部门分发到对应的 Reducer 上处理 |
2.10 CLUSTER BY
如果 SORT BY 和 DISTRIBUTE BY 指定的是相同字段,且 SORT BY 排序规则是 ASC,此时可以使用 CLUSTER BY 进行替换,同时 CLUSTER BY 可以保证数据在全局是有序的。
1 | SELECT empno, deptno, sal FROM emp CLUSTER BY deptno ; |
三、多表联结查询
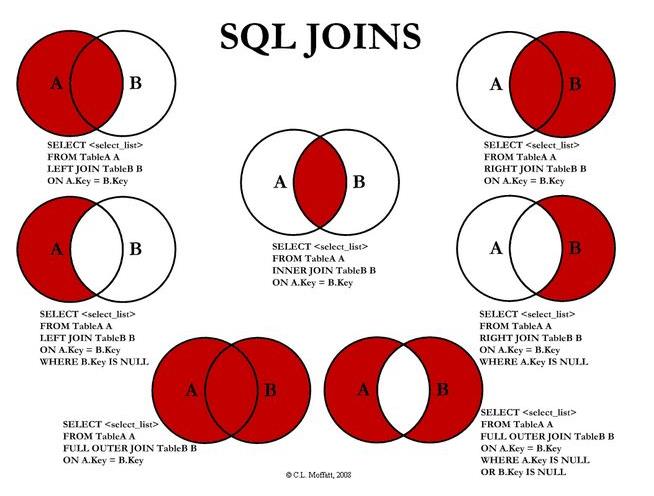
Hive 支持内连接,外连接,左外连接,右外连接,笛卡尔连接,这和传统数据库中的概念是一致的,可以参见下图。
需要特别强调:JOIN 语句的关联条件必须用 ON 指定,不能用 WHERE 指定,否则就会先做笛卡尔积,再过滤,这会导致你得不到预期的结果 (下面的演示会有说明)。
3.1 INNER JOIN
1 | -- 查询员工编号为 7369 的员工的详细信息 |
3.2 LEFT OUTER JOIN
LEFT OUTER JOIN 和 LEFT JOIN 是等价的。
1 | -- 左连接 |
3.3 RIGHT OUTER JOIN
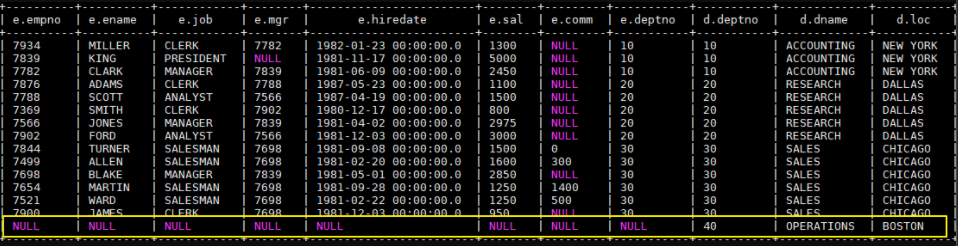
1 | --右连接 |
执行右连接后,由于 40 号部门下没有任何员工,所以此时员工信息为 NULL。这个查询可以很好的复述上面提到的——JOIN 语句的关联条件必须用 ON 指定,不能用 WHERE 指定。你可以把 ON 改成 WHERE,你会发现无论如何都查不出 40 号部门这条数据,因为笛卡尔运算不会有 (NULL, 40) 这种情况。
3.4 FULL OUTER JOIN
1 | SELECT e.*,d.* |
3.5 LEFT SEMI JOIN
LEFT SEMI JOIN (左半连接)是 IN/EXISTS 子查询的一种更高效的实现。
- JOIN 子句中右边的表只能在 ON 子句中设置过滤条件;
- 查询结果只包含左边表的数据,所以只能 SELECT 左表中的列。
1 | -- 查询在纽约办公的所有员工信息 |
3.6 JOIN
笛卡尔积连接,这个连接日常的开发中可能很少遇到,且性能消耗比较大,基于这个原因,如果在严格模式下 (hive.mapred.mode = strict),Hive 会阻止用户执行此操作。
1 | SELECT * FROM emp JOIN dept; |
四、JOIN优化
4.1 STREAMTABLE
在多表进行联结的时候,如果每个 ON 字句都使用到共同的列(如下面的 b.key),此时 Hive 会进行优化,将多表 JOIN 在同一个 map / reduce 作业上进行。同时假定查询的最后一个表(如下面的 c 表)是最大的一个表,在对每行记录进行 JOIN 操作时,它将尝试将其他的表缓存起来,然后扫描最后那个表进行计算。因此用户需要保证查询的表的大小从左到右是依次增加的。
1 | `SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key) JOIN c ON (c.key = b.key)` |
然后,用户并非需要总是把最大的表放在查询语句的最后面,Hive 提供了 /*+ STREAMTABLE() */ 标志,用于标识最大的表,示例如下:
1 | SELECT /*+ STREAMTABLE(d) */ e.*,d.* |
4.2 MAPJOIN
如果所有表中只有一张表是小表,那么 Hive 把这张小表加载到内存中。这时候程序会在 map 阶段直接拿另外一个表的数据和内存中表数据做匹配,由于在 map 就进行了 JOIN 操作,从而可以省略 reduce 过程,这样效率可以提升很多。Hive 中提供了 /*+ MAPJOIN() */ 来标记小表,示例如下:
1 | SELECT /*+ MAPJOIN(d) */ e.*,d.* |
五、SELECT的其他用途
查看当前数据库:
1 | SELECT current_database() |
六、本地模式
在上面演示的语句中,大多数都会触发 MapReduce, 少部分不会触发,比如 select * from emp limit 5 就不会触发 MR,此时 Hive 只是简单的读取数据文件中的内容,然后格式化后进行输出。在需要执行 MapReduce 的查询中,你会发现执行时间可能会很长,这时候你可以选择开启本地模式。
1 | --本地模式默认关闭,需要手动开启此功能 |
启用后,Hive 将分析查询中每个 map-reduce 作业的大小,如果满足以下条件,则可以在本地运行它:
- 作业的总输入大小低于:hive.exec.mode.local.auto.inputbytes.max(默认为 128MB);
- map-tasks 的总数小于:hive.exec.mode.local.auto.tasks.max(默认为 4);
- 所需的 reduce 任务总数为 1 或 0。
因为我们测试的数据集很小,所以你再次去执行上面涉及 MR 操作的查询,你会发现速度会有显著的提升。
参考资料
参考
- https://github.com/RealTommyHu/BigData-Notes/blob/master/notes/Hive简介及核心概念.md
- https://github.com/RealTommyHu/BigData-Notes/blob/master/notes/installation/Linux环境下Hive的安装部署.md
- https://github.com/RealTommyHu/BigData-Notes/blob/master/notes/HiveCLI和Beeline命令行的基本使用.md
- https://github.com/RealTommyHu/BigData-Notes/blob/master/notes/BigData-Notes/blob/master/notes/Hive常用DDL操作.md
- https://github.com/RealTommyHu/BigData-Notes/blob/master/notes/Hive分区表和分桶表.md
- https://github.com/RealTommyHu/BigData-Notes/blob/master/notes/Hive视图和索引.md
- https://github.com/RealTommyHu/BigData-Notes/blob/master/notes/Hive常用DML操作.md
- https://github.com/RealTommyHu/BigData-Notes/blob/master/notes/Hive数据查询详解.md