Spark简介
一、简介
Apache Spark是继 MapReduce 之后,最为广泛使用的分布式计算框架。相对于 MapReduce 的批处理计算,可以带来上百倍的性能提升。
二、特点
具有以下特点:
- 多语言支持:Java、Scala、Python。
- 支持批处理、流处理。
- 丰富的类库支持:SQL,MLlib,GraphX,Spark Streaming。
- 丰富的部署模式:本地模式、集群模式,也支持在Hadoop、Mesos、Kubernetes上运行。
- 多数据源支持:支持访问HDFS、HBase、Hive等数百个数据源中的数据。
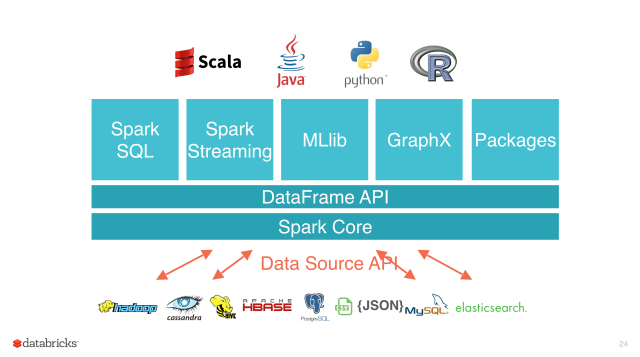
三、集群架构
| Term(术语) | Meaning(含义) |
|---|---|
| Application | Spark 应用程序,由集群上的一个 Driver 节点和多个 Executor 节点组成。 |
| Driver program | 主应用程序,该进程运行应用的 main() 方法并且创建 SparkContext |
| Cluster manager | 集群资源管理器(例如,Standlone Manager,Mesos,YARN) |
| Worker node | 执行计算任务的工作节点 |
| Executor | 位于工作节点上的应用进程,负责执行计算任务并且将输出数据保存到内存或者磁盘中 |
| Task | 被发送到 Executor 中的工作单元 |
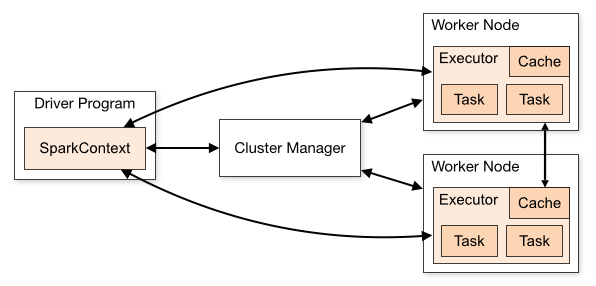
执行过程:
- 用户程序创建 SparkContext 后,它会连接到集群资源管理器,集群资源管理器会为用户程序分配计算资源,并启动 Executor;
- Driver 将计算程序划分为不同的执行阶段和多个 Task,之后将 Task 发送给 Executor;
- Executor 负责执行 Task,并将执行状态汇报给 Driver,同时也会将当前节点资源的使用情况汇报给集群资源管理器。
四、核心组件
Spark 基于 Spark Core 扩展了四个核心组件,分别用于满足不同领域的计算需求。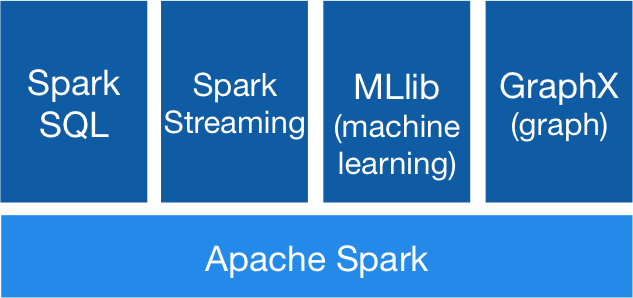
1 Spark SQL
Spark SQL 主要用于结构化数据的处理。其具有以下特点:
- 允许使用 SQL 或 DataFrame API 对结构化数据进行查询;
- 支持多种数据源,包括 Hive,Avro,Parquet,ORC,JSON 和 JDBC;
- 支持 HiveQL 语法以及用户自定义函数 (UDF),允许你访问现有的 Hive 仓库;
- 支持标准的 JDBC 和 ODBC 连接;
- 支持优化器,列式存储和代码生成等特性,以提高查询效率。
2 Spark Streaming
Spark Streaming 主要用于快速构建可扩展,高吞吐量,高容错的流处理程序。支持从 HDFS,Flume,Kafka,Twitter 和 ZeroMQ 读取数据,并进行处理。
Spark Streaming 的本质是微批处理,它将数据流进行极小粒度的拆分,拆分为多个批处理,从而达到接近于流处理的效果。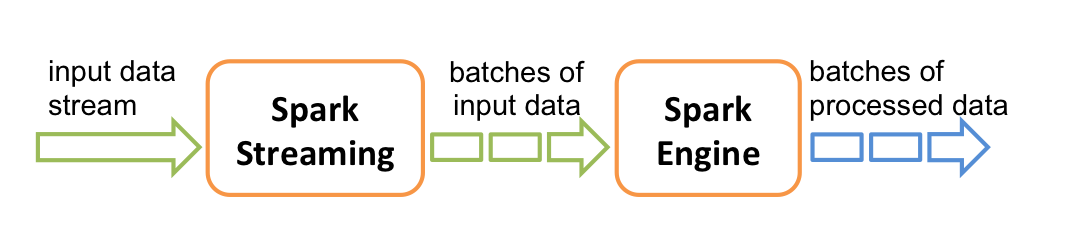
3 MLlib
MLlib 是 Spark 的机器学习库。其设计目标是使得机器学习变得简单且可扩展。它提供了以下工具:
- 常见的机器学习算法:如分类,回归,聚类和协同过滤;
- 特征化:特征提取,转换,降维和选择;
- 管道:用于构建,评估和调整 ML 管道的工具;
- 持久性:保存和加载算法,模型,管道数据;
- 实用工具:线性代数,统计,数据处理等。
4 Graphx
GraphX 是 Spark 中用于图计算和图并行计算的新组件。在高层次上,GraphX 通过引入一个新的图抽象来扩展 RDD(一种具有附加到每个顶点和连边的属性的定向多重图形)。为了支持图计算,GraphX 提供了一组基本运算符(如: subgraph,joinVertices 和 aggregateMessages)以及优化后的 Pregel API。此外,GraphX 还包括越来越多的图算法和构建器,以简化图分析任务。
弹性分布式数据集RDDs
一、RDD简介
Resilient Distributed Datasets,只读、分区记录的集合。支持并行,可由外部数据集或者其它RDD转换。有以下特性:
- 由一个或多个分区组成,每个分区被一个计算任务处理,可在创建RDD时指定分区个数,未指定则默认采用程序所分配到的CPU核心数。
- 有一个函数compute来计算分区。
- RDD的每次转换都会生成一个新的依赖关系,并且RDD会保存彼此间的依赖关系,在部分分区数据丢失后可通过这种依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
- Key-Value型的RDD拥有分区器来决定数据存储的分区,支持哈希分区和范围分区。
- 有一个可选的优先位置列表存储每个分区的优先位置,对于一个HDFS文件来说,这个列表保存的就是每个分区所在的块的位置,按“移动数据不如移动计算”的理念,在任务调度时会尽可能将计算任务分配到其所要处理数据块的存储位置。
RDD[T] 抽象类的部分相关代码如下:
1 | // 由子类实现以计算给定分区 |
二、创建RDD
RDD有两种创建方式,分别介绍如下:
2.1 由现有集合创建
这里使用 spark-shell 进行测试,启动命令如下:
1 | spark-shell --master local[4] |
启动 spark-shell 后,程序会自动创建应用上下文,相当于执行了下面的 Scala 语句:
1 | val conf = new SparkConf().setAppName("Spark shell").setMaster("local[4]") |
由现有集合创建 RDD,你可以在创建时指定其分区个数,如果没有指定,则采用程序所分配到的 CPU 的核心数:
1 | val data = Array(1, 2, 3, 4, 5) |
2.2 应用外部存储系统中的数据集
引用外部存储系统中的数据集,例如本地文件系统,HDFS,HBase 或支持 Hadoop InputFormat 的任何数据源。
1 | val fileRDD = sc.textFile("/usr/file/emp.txt") |
使用外部存储系统时需要注意以下两点:
- 如果在集群环境下从本地文件系统读取数据,则要求该文件必须在集群中所有机器上都存在,且路径相同;
- 支持目录路径,支持压缩文件,支持使用通配符。
2.3 textFile & wholeTextFiles
两者都可以用来读取外部文件,但是返回格式是不同的:
- textFile:其返回格式是 RDD[String] ,返回的是就是文件内容,RDD 中每一个元素对应一行数据;
- wholeTextFiles:其返回格式是 RDD[(String, String)],元组中第一个参数是文件路径,第二个参数是文件内容;
- 两者都提供第二个参数来控制最小分区数;
- 从 HDFS 上读取文件时,Spark 会为每个块创建一个分区。
1 | def textFile(path: String,minPartitions: Int = defaultMinPartitions): RDD[String] = withScope {...} |
三、操作RDD
RDD 支持两种类型的操作:transformations(转换,从现有数据集创建新数据集)和 actions(在数据集上运行计算后将值返回到驱动程序)。RDD 中的所有转换操作都是惰性的,它们只是记住这些转换操作,但不会立即执行,只有遇到 action 操作后才会真正的进行计算,这类似于函数式编程中的惰性求值。
1 | val list = List(1, 2, 3) |
四、缓存RDD
4.1 缓存级别
Spark 速度非常快的一个原因是 RDD 支持缓存。成功缓存后,如果之后的操作使用到了该数据集,则直接从缓存中获取。虽然缓存也有丢失的风险,但是由于 RDD 之间的依赖关系,如果某个分区的缓存数据丢失,只需要重新计算该分区即可。
Spark 支持多种缓存级别 :
| Storage Level 存储级别 | Meaning(含义) |
|---|---|
| MEMORY_ONLY | 默认的缓存级别,将 RDD 以反序列化的 Java 对象的形式存储在 JVM 中。如果内存空间不够,则部分分区数据将不再缓存。 |
| MEMORY_AND_DISK | 将 RDD 以反序列化的 Java 对象的形式存储 JVM 中。如果内存空间不够,将未缓存的分区数据存储到磁盘,在需要使用这些分区时从磁盘读取。 |
| MEMORY_ONLY_SER | 将 RDD 以序列化的 Java 对象的形式进行存储(每个分区为一个 byte 数组)。这种方式比反序列化对象节省存储空间,但在读取时会增加 CPU 的计算负担。仅支持 Java 和 Scala 。 |
| MEMORY_AND_DISK_SER | 类似于 MEMORY_ONLY_SER,但是溢出的分区数据会存储到磁盘,而不是在用到它们时重新计算。仅支持 Java 和 Scala。 |
| DISK_ONLY | 只在磁盘上缓存 RDD |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2, etc | 与上面的对应级别功能相同,但是会为每个分区在集群中的两个节点上建立副本。 |
| OFF_HEAP | 与 MEMORY_ONLY_SER 类似,但将数据存储在堆外内存中。这需要启用堆外内存。 |
启动堆外内存需要配置两个参数:
- spark.memory.offHeap.enabled :是否开启堆外内存,默认值为 false,需要设置为 true;
- spark.memory.offHeap.size : 堆外内存空间的大小,默认值为 0,需要设置为正值。
4.2 使用缓存
缓存数据的方法有两个:persist 和 cache 。cache 内部调用的也是 persist,它是 persist 的特殊化形式,等价于 persist(StorageLevel.MEMORY_ONLY)。示例如下:
1 | // 所有存储级别均定义在 StorageLevel 对象中 |
一个已分配存储级别的RDD不能直接更改存储级别。
4.3 移除缓存
- Spark 自动监视每个节点上的缓存使用,按照最近最少使用(LRU)的规则删除旧数据分区。
- 也可以使用 RDD.unpersist() 方法进行手动删除。
五、理解shuffle
5.1 shuffle介绍
Spark 中,一个任务对应一个分区,通常不会跨分区操作数据。但如果遇到 reduceByKey 等操作,Spark 必须从所有分区读取数据,并查找所有键的所有值,然后汇总在一起以计算每个键的最终结果 ,这称为 Shuffle。
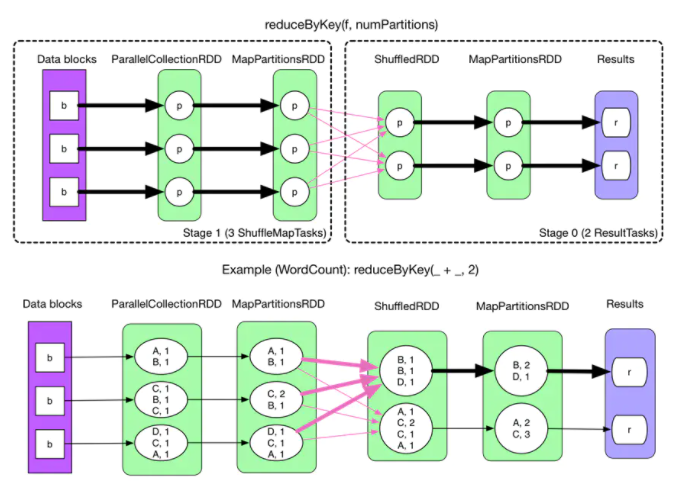
5.2 Shuffle的影响
Shuffle 是项昂贵的操作,跨节点操作数据,涉及磁盘 I/O,网络 I/O,和数据序列化。消耗大量的堆内存,用堆内存来临时存储需要网络传输的数据。在磁盘上生成大量中间文件,避免在计算时重复创建 Shuffle 文件。如果应用程序长期保留对这些 RDD 的引用,则垃圾回收可能在很长一段时间后才会发生,这意味着长时间运行的 Spark 作业可能会占用大量磁盘空间,通常可以使用 spark.local.dir 参数来指定这些临时文件的存储目录。
5.3 导致Shuffle的操作
Shuffle 操作对性能的影响比较大,所以需要特别注意使用,导致Shuffle的操作:
- 涉及到重新分区操作: 如 repartition 和 coalesce;
- 所有涉及到 ByKey 的操作:如 groupByKey 和 reduceByKey,但 countByKey 除外;
- 联结操作:如 cogroup 和 join。
五、宽依赖和窄依赖
RDD 和它的父 RDD(s) 之间的依赖关系分为两种不同的类型:
- 窄依赖 (narrow dependency):父 RDDs 的一个分区最多被子 RDDs 一个分区所依赖;
- 宽依赖 (wide dependency):父 RDDs 的一个分区可以被子 RDDs 的多个子分区所依赖。
如下图,每一个方框表示一个 RDD,带有颜色的矩形表示分区:
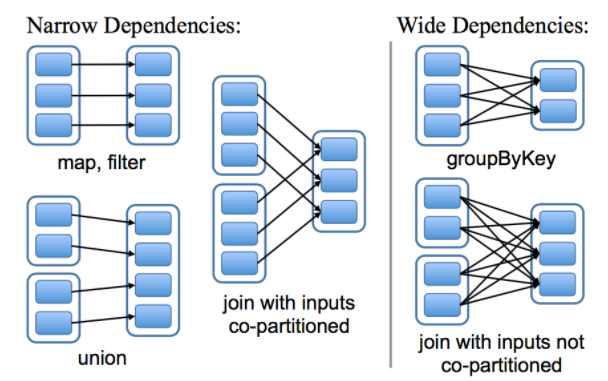
区分这两种依赖是非常有用的:
- 窄依赖允许在一个集群节点上以流水线的方式(pipeline)对父分区数据进行计算,例如先执行 map 操作,然后执行 filter 操作。
- 而宽依赖则需要计算好所有父分区的数据,然后再在节点之间进行 Shuffle,这与 MapReduce 类似。
- 窄依赖能够更有效地进行数据恢复,因为只需重新对丢失分区的父分区进行计算,且不同节点之间可以并行计算;
- 而对于宽依赖而言,如果数据丢失,则需要对所有父分区数据进行计算并再次 Shuffle。
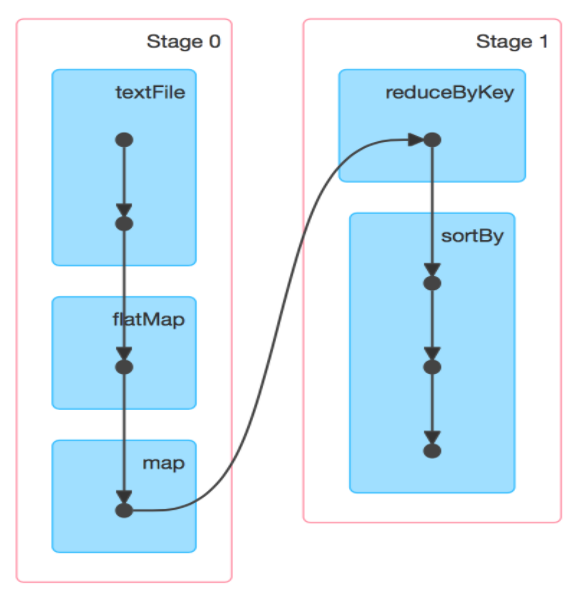
六、DAG的生成
RDD(s)及其之间的依赖关系组成了 DAG(有向无环图),通过依赖关系,如果一个 RDD 的部分或者全部计算结果丢失了,也可以重新进行计算。Spark根据依赖关系的不同将 DAG 划分为不同的计算阶段 (Stage):
- 窄依赖,分区的依赖关系是确定的,其转换操作可以在同一个线程执行,所以可以划分到同一个执行阶段;
- 宽依赖,由于 Shuffle 的存在,只能在父 RDD(s) 被 Shuffle 处理完成后,才能开始接下来的计算,因此遇到宽依赖就需要重新划分阶段。
Transformation 和 Action 常用算子
一、Transformation
spark 常用的 Transformation 算子如下表:
| Transformation 算子 | Meaning(含义) |
|---|---|
| map(func) | 对原 RDD 中每个元素运用 func 函数,并生成新的 RDD |
| filter(func) | 对原 RDD 中每个元素使用func 函数进行过滤,并生成新的 RDD |
| flatMap(func) | 与 map 类似,但是每一个输入的 item 被映射成 0 个或多个输出的 items( func 返回类型需要为 Seq )。 |
| mapPartitions(func) | 与 map 类似,但函数单独在 RDD 的每个分区上运行, func函数的类型为 Iterator<T> => Iterator<U> ,其中 T 是 RDD 的类型,即 RDD[T] |
| mapPartitionsWithIndex(func) | 与 mapPartitions 类似,但 func 类型为 (Int, Iterator<T>) => Iterator<U> ,其中第一个参数为分区索引 |
| sample(withReplacement, fraction, seed) | 数据采样,有三个可选参数:设置是否放回(withReplacement)、采样的百分比(fraction)、随机数生成器的种子(seed); |
| union(otherDataset) | 合并两个 RDD |
| intersection(otherDataset) | 求两个 RDD 的交集 |
| distinct([numTasks])) | 去重 |
| groupByKey([numTasks]) | 按照 key 值进行分区,即在一个 (K, V) 对的 dataset 上调用时,返回一个 (K, Iterable<V>) Note: 如果分组是为了在每一个 key 上执行聚合操作(例如,sum 或 average),此时使用 reduceByKey 或 aggregateByKey 性能会更好Note: 默认情况下,并行度取决于父 RDD 的分区数。可以传入 numTasks 参数进行修改。 |
| reduceByKey(func, [numTasks]) | 按照 key 值进行分组,并对分组后的数据执行归约操作。 |
| aggregateByKey(zeroValue,numPartitions)(seqOp, combOp, [numTasks]) | 当调用(K,V)对的数据集时,返回(K,U)对的数据集,其中使用给定的组合函数和 zeroValue 聚合每个键的值。与 groupByKey 类似,reduce 任务的数量可通过第二个参数进行配置。 |
| sortByKey([ascending], [numTasks]) | 按照 key 进行排序,其中的 key 需要实现 Ordered 特质,即可比较 |
| join(otherDataset, [numTasks]) | 在一个 (K, V) 和 (K, W) 类型的 dataset 上调用时,返回一个 (K, (V, W)) pairs 的 dataset,等价于内连接操作。如果想要执行外连接,可以使用 leftOuterJoin, rightOuterJoin 和 fullOuterJoin 等算子。 |
| cogroup(otherDataset, [numTasks]) | 在一个 (K, V) 对的 dataset 上调用时,返回一个 (K, (Iterable<V>, Iterable<W>)) tuples 的 dataset。 |
| cartesian(otherDataset) | 在一个 T 和 U 类型的 dataset 上调用时,返回一个 (T, U) 类型的 dataset(即笛卡尔积)。 |
| coalesce(numPartitions) | 将 RDD 中的分区数减少为 numPartitions。 |
| repartition(numPartitions) | 随机重新调整 RDD 中的数据以创建更多或更少的分区,并在它们之间进行平衡。 |
| repartitionAndSortWithinPartitions(partitioner) | 根据给定的 partitioner(分区器)对 RDD 进行重新分区,并对分区中的数据按照 key 值进行排序。这比调用 repartition 然后再 sorting(排序)效率更高,因为它可以将排序过程推送到 shuffle 操作所在的机器。 |
下面分别给出这些算子的基本使用示例:
1.1 map
对原 RDD 中每个元素运用 func 函数,并生成新的 RDD。
1 | val list = List(1,2,3) |
1.2 filter
对原 RDD 中每个元素使用func 函数进行过滤,并生成新的 RDD 。
1 | val list = List(3, 6, 9, 10, 12, 21) |
1.3 flatMap
flatMap(func) 与 map 类似,但每一个输入的 item 会被映射成 0 个或多个输出的 items( func 返回类型需要为 Seq)。
1 | val list = List(List(1, 2), List(3), List(), List(4, 5)) |
flatMap 这个算子在日志分析中使用概率非常高,这里进行一下演示:拆分输入的每行数据为单个单词,并赋值为 1,代表出现一次,之后按照单词分组并统计其出现总次数,代码如下:
1 | val lines = List("spark flume spark", |
1.4 mapPartitions
与 map 类似,但函数单独在 RDD 的每个分区上运行, func函数的类型为 Iterator<T> => Iterator<U> (其中 T 是 RDD 的类型),即输入和输出都必须是可迭代类型。
1 | val list = List(1, 2, 3, 4, 5, 6) |
1.5 mapPartitionsWithIndex
与 mapPartitions 类似,但 func 类型为 (Int, Iterator<T>) => Iterator<U> ,其中第一个参数为分区索引。
1 | val list = List(1, 2, 3, 4, 5, 6) |
1.6 sample
数据采样。有三个可选参数:设置是否放回 (withReplacement)、采样的百分比 (fraction)、随机数生成器的种子 (seed) :
1 | val list = List(1, 2, 3, 4, 5, 6) |
1.7 union
合并两个 RDD:
1 | val list1 = List(1, 2, 3) |
1.8 intersection
求两个 RDD 的交集:
1 | val list1 = List(1, 2, 3, 4, 5) |
1.9 distinct
去重:
1 | val list = List(1, 2, 2, 4, 4) |
1.10 groupByKey
按照键进行分组:
1 | val list = List(("hadoop", 2), ("spark", 3), ("spark", 5), ("storm", 6), ("hadoop", 2)) |
1.11 reduceByKey
按照键进行归约操作:
1 | val list = List(("hadoop", 2), ("spark", 3), ("spark", 5), ("storm", 6), ("hadoop", 2)) |
1.12 sortBy & sortByKey
按照键进行排序:
1 | val list01 = List((100, "hadoop"), (90, "spark"), (120, "storm")) |
按照指定元素进行排序:
1 | val list02 = List(("hadoop",100), ("spark",90), ("storm",120)) |
1.13 join
在一个 (K, V) 和 (K, W) 类型的 Dataset 上调用时,返回一个 (K, (V, W)) 的 Dataset,等价于内连接操作。如果想要执行外连接,可以使用 leftOuterJoin, rightOuterJoin 和 fullOuterJoin 等算子。
1 | val list01 = List((1, "student01"), (2, "student02"), (3, "student03")) |
1.14 cogroup
cogroup(otherDataset, [numTasks])
在一个 (K, V) 对的 Dataset 上调用时,返回多个类型为 (K, (Iterable<V>, Iterable<W>)) 的元组所组成的 Dataset。
1 | val list01 = List((1, "a"),(1, "a"), (2, "b"), (3, "e")) |
1.15 cartesian
计算笛卡尔积:
1 | val list1 = List("A", "B", "C") |
1.16 aggregateByKey
当调用(K,V)对的数据集时,返回(K,U)对的数据集,其中使用给定的组合函数和 zeroValue 聚合每个键的值。与 groupByKey 类似,reduce 任务的数量可通过第二个参数 numPartitions 进行配置。示例如下:
1 | // 为了清晰,以下所有参数均使用具名传参 |
这里使用了 numSlices = 2 指定 aggregateByKey 父操作 parallelize 的分区数量为 2,其执行流程如下:
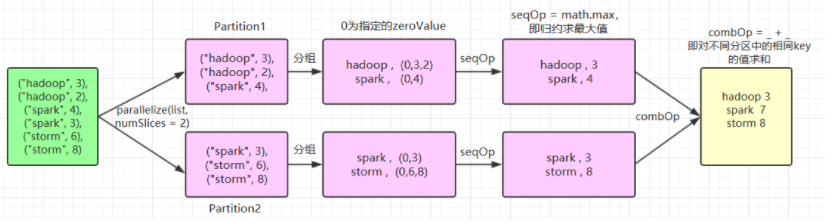
基于同样的执行流程,如果 numSlices = 1,则意味着只有输入一个分区,则其最后一步 combOp 相当于是无效的,执行结果为:
1 | (hadoop,3) |
同样的,如果每个单词对一个分区,即 numSlices = 6,此时相当于求和操作,执行结果为:
1 | (hadoop,5) |
aggregateByKey(zeroValue = 0,numPartitions = 3) 的第二个参数 numPartitions 决定的是输出 RDD 的分区数量,想要验证这个问题,可以对上面代码进行改写,使用 getNumPartitions 方法获取分区数量:
1 | sc.parallelize(list,numSlices = 6).aggregateByKey(zeroValue = 0,numPartitions = 3)( |
二、Action
Spark 常用的 Action 算子如下:
| Action(动作) | Meaning(含义) |
|---|---|
| reduce(func) | 使用函数func执行归约操作 |
| collect() | 以一个 array 数组的形式返回 dataset 的所有元素,适用于小结果集。 |
| count() | 返回 dataset 中元素的个数。 |
| first() | 返回 dataset 中的第一个元素,等价于 take(1)。 |
| take(n) | 将数据集中的前 n 个元素作为一个 array 数组返回。 |
| takeSample(withReplacement, num, [seed]) | 对一个 dataset 进行随机抽样 |
| takeOrdered(n, [ordering]) | 按自然顺序(natural order)或自定义比较器(custom comparator)排序后返回前 n 个元素。只适用于小结果集,因为所有数据都会被加载到驱动程序的内存中进行排序。 |
| saveAsTextFile(path) | 将 dataset 中的元素以文本文件的形式写入本地文件系统、HDFS 或其它 Hadoop 支持的文件系统中。Spark 将对每个元素调用 toString 方法,将元素转换为文本文件中的一行记录。 |
| saveAsSequenceFile(path) | 将 dataset 中的元素以 Hadoop SequenceFile 的形式写入到本地文件系统、HDFS 或其它 Hadoop 支持的文件系统中。该操作要求 RDD 中的元素需要实现 Hadoop 的 Writable 接口。对于 Scala 语言而言,它可以将 Spark 中的基本数据类型自动隐式转换为对应 Writable 类型。(目前仅支持 Java and Scala) |
| saveAsObjectFile(path) | 使用 Java 序列化后存储,可以使用 SparkContext.objectFile() 进行加载。(目前仅支持 Java and Scala) |
| countByKey() | 计算每个键出现的次数。 |
| foreach(func) | 遍历 RDD 中每个元素,并对其执行fun函数 |
2.1 reduce
使用函数func执行归约操作:
1 | val list = List(1, 2, 3, 4, 5) |
2.2 takeOrdered
按自然顺序(natural order)或自定义比较器(custom comparator)排序后返回前 n 个元素。需要注意的是 takeOrdered 使用隐式参数进行隐式转换,以下为其源码。所以在使用自定义排序时,需要继承 Ordering[T] 实现自定义比较器,然后将其作为隐式参数引入。
1 | def takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T] = withScope { |
自定义规则排序:
1 | // 继承 Ordering[T],实现自定义比较器,按照 value 值的长度进行排序 |
2.3 countByKey
计算每个键出现的次数:
1 | val list = List(("hadoop", 10), ("hadoop", 10), ("storm", 3), ("storm", 3), ("azkaban", 1)) |
2.4 saveAsTextFile
将 dataset 中的元素以文本文件的形式写入本地文件系统、HDFS 或其它 Hadoop 支持的文件系统中。Spark 将对每个元素调用 toString 方法,将元素转换为文本文件中的一行记录。
1 | val list = List(("hadoop", 10), ("hadoop", 10), ("storm", 3), ("storm", 3), ("azkaban", 1)) |
Spark累加器与广播变量
一、简介
在 Spark 中,提供了两种类型的共享变量:累加器 (accumulator) 与广播变量 (broadcast variable):
- 累加器:用来对信息进行聚合,主要用于累计计数等场景;
- 广播变量:主要用于在节点间高效分发大对象。
二、累加器
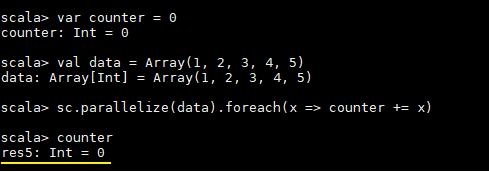
这里先看一个具体的场景,对于正常的累计求和,如果在集群模式中使用下面的代码进行计算,会发现执行结果并非预期:
1 | var counter = 0 |
counter 最后的结果是 0,导致这个问题的主要原因是闭包。
2.1 理解闭包
1. Scala 中闭包的概念
这里先介绍一下 Scala 中关于闭包的概念:
1 | var more = 10 |
如上函数 addMore 中有两个变量 x 和 more:
- x : 是一个绑定变量 (bound variable),因为其是该函数的入参,在函数的上下文中有明确的定义;
- more : 是一个自由变量 (free variable),因为函数字面量本生并没有给 more 赋予任何含义。
按照定义:在创建函数时,如果需要捕获自由变量,那么包含指向被捕获变量的引用的函数就被称为闭包函数。
2. Spark 中的闭包
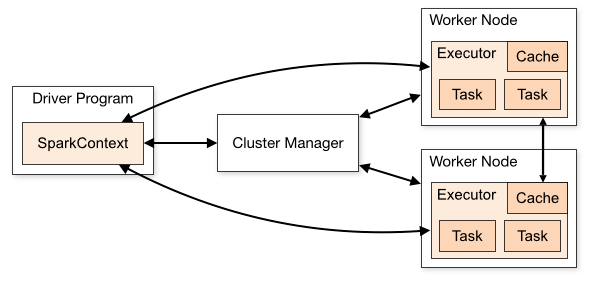
在实际计算时,Spark 会将对 RDD 操作分解为 Task,Task 运行在 Worker Node 上。在执行之前,Spark 会对任务进行闭包,如果闭包内涉及到自由变量,则程序会进行拷贝,并将副本变量放在闭包中,之后闭包被序列化并发送给每个执行者。因此,当在 foreach 函数中引用 counter 时,它将不再是 Driver 节点上的 counter,而是闭包中的副本 counter,默认情况下,副本 counter 更新后的值不会回传到 Driver,所以 counter 的最终值仍然为零。
需要注意的是:在 Local 模式下,有可能执行 foreach 的 Worker Node 与 Diver 处在相同的 JVM,并引用相同的原始 counter,这时候更新可能是正确的,但是在集群模式下一定不正确。所以在遇到此类问题时应优先使用累加器。
累加器的原理实际上很简单:就是将每个副本变量的最终值传回 Driver,由 Driver 聚合后得到最终值,并更新原始变量。
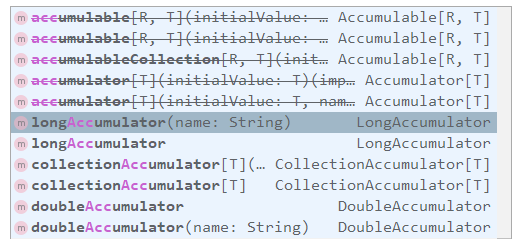
2.2 使用累加器
SparkContext 中定义了所有创建累加器的方法,需要注意的是:被中横线划掉的累加器方法在 Spark 2.0.0 之后被标识为废弃。
使用示例和执行结果分别如下:
1 | val data = Array(1, 2, 3, 4, 5) |

三、广播变量
在上面介绍中闭包的过程中我们说道每个 Task 任务的闭包都会持有自由变量的副本,如果变量很大且 Task 任务很多的情况下,这必然会对网络 IO 造成压力,为了解决这个情况,Spark 提供了广播变量。
广播变量的做法很简单:就是不把副本变量分发到每个 Task 中,而是将其分发到每个 Executor,Executor 中的所有 Task 共享一个副本变量。
1 | // 把一个数组定义为一个广播变量 |
SparkSQL_Dataset和DataFrame简介
一、Spark SQL简介
Spark SQL 是 Spark 中的一个子模块,主要用于操作结构化数据。它具有以下特点:
- 能够将 SQL 查询与 Spark 程序无缝混合,允许您使用 SQL 或 DataFrame API 对结构化数据进行查询;
- 支持多种开发语言;
- 支持多达上百种的外部数据源,包括 Hive,Avro,Parquet,ORC,JSON 和 JDBC 等;
- 支持 HiveQL 语法以及 Hive SerDes 和 UDF,允许你访问现有的 Hive 仓库;
- 支持标准的 JDBC 和 ODBC 连接;
- 支持优化器,列式存储和代码生成等特性;
- 支持扩展并能保证容错。

二、DataFrame & DataSet
2.1 DataFrame
为了支持结构化数据的处理,Spark SQL 提供了新的数据结构 DataFrame。DataFrame 是一个由具名列组成的数据集。它在概念上等同于关系数据库中的表或 R/Python 语言中的 data frame。 由于 Spark SQL 支持多种语言的开发,所以每种语言都定义了 DataFrame 的抽象,主要如下:
| 语言 | 主要抽象 |
|---|---|
| Scala | Dataset[T] & DataFrame (Dataset[Row] 的别名) |
| Java | Dataset[T] |
| Python | DataFrame |
| R | DataFrame |
2.2 DataFrame 对比 RDDs
DataFrame 和 RDDs 最主要的区别在于一个面向的是结构化数据,一个面向的是非结构化数据,它们内部的数据结构如下:
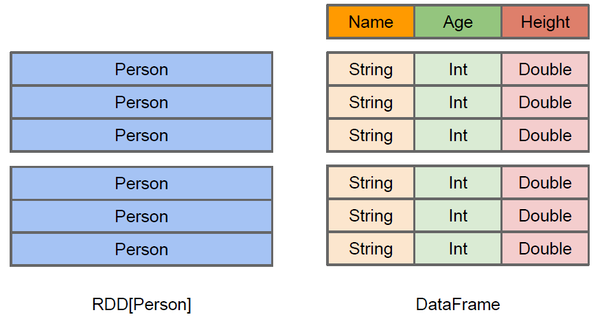
DataFrame 内部的有明确 Scheme 结构,即列名、列字段类型都是已知的,这带来的好处是可以减少数据读取以及更好地优化执行计划,从而保证查询效率。
DataFrame 和 RDDs 应该如何选择?
- 如果你想使用函数式编程而不是 DataFrame API,则使用 RDDs;
- 如果你的数据是非结构化的 (比如流媒体或者字符流),则使用 RDDs,
- 如果你的数据是结构化的 (如 RDBMS 中的数据) 或者半结构化的 (如日志),出于性能上的考虑,应优先使用 DataFrame。
2.3 DataSet
Dataset 也是分布式的数据集合,在 Spark 1.6 版本被引入,它集成了 RDD 和 DataFrame 的优点,具备强类型的特点,同时支持 Lambda 函数,但只能在 Scala 和 Java 语言中使用。在 Spark 2.0 后,为了方便开发者,Spark 将 DataFrame 和 Dataset 的 API 融合到一起,提供了结构化的 API(Structured API),即用户可以通过一套标准的 API 就能完成对两者的操作。
这里注意一下:DataFrame 被标记为 Untyped API,而 DataSet 被标记为 Typed API,后文会对两者做出解释。
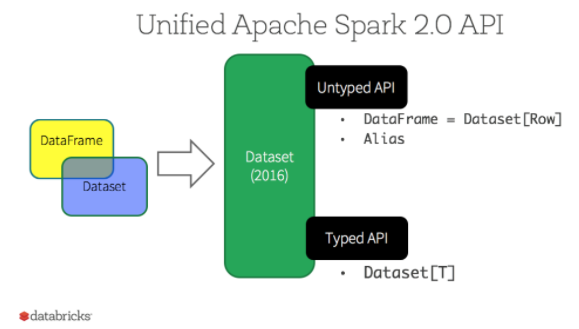
2.4 静态类型与运行时类型安全
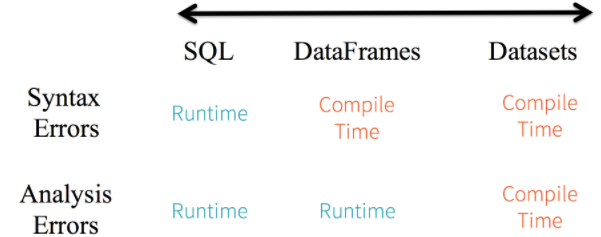
静态类型 (Static-typing) 与运行时类型安全 (runtime type-safety) 主要表现如下:
在实际使用中,如果你用的是 Spark SQL 的查询语句,则直到运行时你才会发现有语法错误,而如果你用的是 DataFrame 和 Dataset,则在编译时就可以发现错误 (这节省了开发时间和整体代价)。DataFrame 和 Dataset 主要区别在于:
在 DataFrame 中,当你调用了 API 之外的函数,编译器就会报错,但如果你使用了一个不存在的字段名字,编译器依然无法发现。而 Dataset 的 API 都是用 Lambda 函数和 JVM 类型对象表示的,所有不匹配的类型参数在编译时就会被发现。
以上这些最终都被解释成关于类型安全图谱,对应开发中的语法和分析错误。在图谱中,Dataset 最严格,但对于开发者来说效率最高。
上面的描述可能并没有那么直观,下面的给出一个 IDEA 中代码编译的示例:
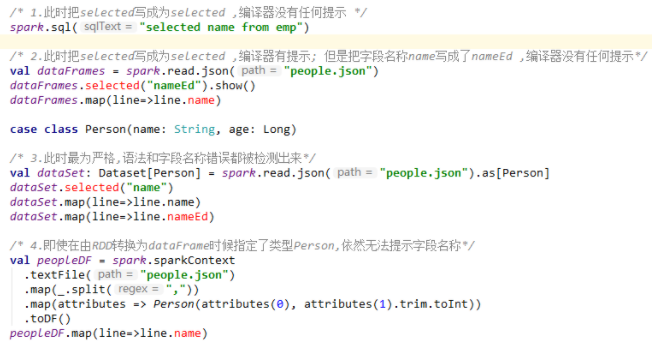
这里一个可能的疑惑是 DataFrame 明明是有确定的 Scheme 结构 (即列名、列字段类型都是已知的),但是为什么还是无法对列名进行推断和错误判断,这是因为 DataFrame 是 Untyped 的。
2.5 Untyped & Typed
在上面我们介绍过 DataFrame API 被标记为 Untyped API,而 DataSet API 被标记为 Typed API。DataFrame 的 Untyped 是相对于语言或 API 层面而言,它确实有明确的 Scheme 结构,即列名,列类型都是确定的,但这些信息完全由 Spark 来维护,Spark 只会在运行时检查这些类型和指定类型是否一致。这也就是为什么在 Spark 2.0 之后,官方推荐把 DataFrame 看做是 DatSet[Row],Row 是 Spark 中定义的一个 trait,其子类中封装了列字段的信息。
相对而言,DataSet 是 Typed 的,即强类型。如下面代码,DataSet 的类型由 Case Class(Scala) 或者 Java Bean(Java) 来明确指定的,在这里即每一行数据代表一个 Person,这些信息由 JVM 来保证正确性,所以字段名错误和类型错误在编译的时候就会被 IDE 所发现。
1 | case class Person(name: String, age: Long) |
三、DataFrame & DataSet & RDDs 总结
这里对三者做一下简单的总结:
- RDDs 适合非结构化数据的处理,而 DataFrame & DataSet 更适合结构化数据和半结构化的处理;
- DataFrame & DataSet 可以通过统一的 Structured API 进行访问,而 RDDs 则更适合函数式编程的场景;
- 相比于 DataFrame 而言,DataSet 是强类型的 (Typed),有着更为严格的静态类型检查;
- DataSets、DataFrames、SQL 的底层都依赖了 RDDs API,并对外提供结构化的访问接口。
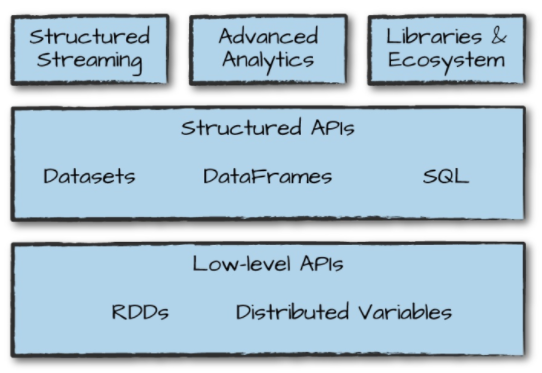
四、Spark SQL的运行原理
DataFrame、DataSet 和 Spark SQL 的实际执行流程都是相同的:
- 进行 DataFrame/Dataset/SQL 编程;
- 如果是有效的代码,即代码没有编译错误,Spark 会将其转换为一个逻辑计划;
- Spark 将此逻辑计划转换为物理计划,同时进行代码优化;
- Spark 然后在集群上执行这个物理计划 (基于 RDD 操作) 。
4.1 逻辑计划(Logical Plan)
执行的第一个阶段是将用户代码转换成一个逻辑计划。它首先将用户代码转换成 unresolved logical plan(未解决的逻辑计划),之所以这个计划是未解决的,是因为尽管您的代码在语法上是正确的,但是它引用的表或列可能不存在。 Spark 使用 analyzer(分析器) 基于 catalog(存储的所有表和 DataFrames 的信息) 进行解析。解析失败则拒绝执行,解析成功则将结果传给 Catalyst 优化器 (Catalyst Optimizer),优化器是一组规则的集合,用于优化逻辑计划,通过谓词下推等方式进行优化,最终输出优化后的逻辑执行计划。
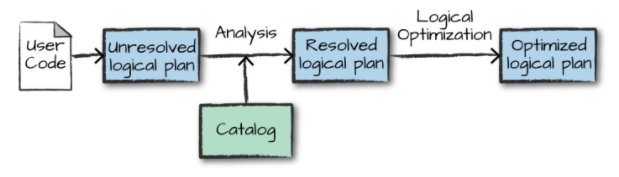
4.2 物理计划(Physical Plan)
得到优化后的逻辑计划后,Spark 就开始了物理计划过程。 它通过生成不同的物理执行策略,并通过成本模型来比较它们,从而选择一个最优的物理计划在集群上面执行的。物理规划的输出结果是一系列的 RDDs 和转换关系 (transformations)。
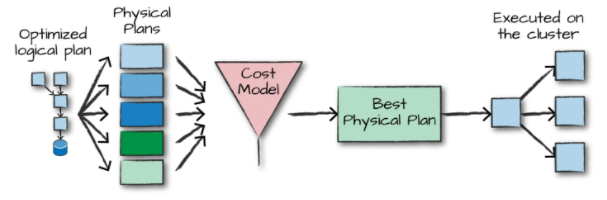
4.3 执行
在选择一个物理计划后,Spark 运行其 RDDs 代码,并在运行时执行进一步的优化,生成本地 Java 字节码,最后将运行结果返回给用户。
Structured API基本使用
一、创建DataFrame和Dataset
1.1 创建DataFrame
Spark 中所有功能的入口点是 SparkSession,可以使用 SparkSession.builder() 创建。创建后应用程序就可以从现有 RDD,Hive 表或 Spark 数据源创建 DataFrame。示例如下:
1 | val spark = SparkSession.builder().appName("Spark-SQL").master("local[2]").getOrCreate() |
可以使用 spark-shell 进行测试,需要注意的是 spark-shell 启动后会自动创建一个名为 spark 的 SparkSession,在命令行中可以直接引用即可:
1.2 创建Dataset
Spark 支持由内部数据集和外部数据集来创建 DataSet,其创建方式分别如下:
1. 由外部数据集创建
1 | // 1.需要导入隐式转换 |
2. 由内部数据集创建
1 | // 1.需要导入隐式转换 |
1.3 由RDD创建DataFrame
Spark 支持两种方式把 RDD 转换为 DataFrame,分别是使用反射推断和指定 Schema 转换:
1. 使用反射推断
1 | // 1.导入隐式转换 |
2. 以编程方式指定Schema
1 | import org.apache.spark.sql.Row |
1.4 DataFrames与Datasets互相转换
Spark 提供了非常简单的转换方法用于 DataFrame 与 Dataset 间的互相转换,示例如下:
1 | DataFrames转Datasets |
二、Columns列操作
2.1 引用列
Spark 支持多种方法来构造和引用列,最简单的是使用 col() 或 column() 函数。
1 | col("colName") |
2.2 新增列
1 | // 基于已有列值新增列 |
2.3 删除列
1 | // 支持删除多个列 |
2.4 重命名列
1 | df.withColumnRenamed("comm", "common").show() |
需要说明的是新增,删除,重命名列都会产生新的 DataFrame,原来的 DataFrame 不会被改变。
三、使用Structured API进行基本查询
1 | // 1.查询员工姓名及工作 |
四、使用Spark SQL进行基本查询
4.1 Spark SQL基本使用
1 | // 1.首先需要将 DataFrame 注册为临时视图 |
4.2 全局临时视图
上面使用 createOrReplaceTempView 创建的是会话临时视图,它的生命周期仅限于会话范围,会随会话的结束而结束。
你也可以使用 createGlobalTempView 创建全局临时视图,全局临时视图可以在所有会话之间共享,并直到整个 Spark 应用程序终止后才会消失。全局临时视图被定义在内置的 global_temp 数据库下,需要使用限定名称进行引用,如 SELECT * FROM global_temp.view1。
1 | // 注册为全局临时视图 |
Spark SQL 外部数据源
一、简介
1.1 多数据源支持
Spark 支持以下六个核心数据源,同时 Spark 社区还提供了多达上百种数据源的读取方式,能够满足绝大部分使用场景。
- CSV
- JSON
- Parquet
- ORC
- JDBC/ODBC connections
- Plain-text files
注:以下所有测试文件均可从本仓库的resources 目录进行下载
1.2 读数据格式
所有读取 API 遵循以下调用格式:
1 | // 格式 |
读取模式有以下三种可选项:
| 读模式 | 描述 |
|---|---|
permissive |
当遇到损坏的记录时,将其所有字段设置为 null,并将所有损坏的记录放在名为 _corruption t_record 的字符串列中 |
dropMalformed |
删除格式不正确的行 |
failFast |
遇到格式不正确的数据时立即失败 |
1.3 写数据格式
1 | // 格式 |
写数据模式有以下四种可选项:
| Scala/Java | 描述 |
|---|---|
SaveMode.ErrorIfExists |
如果给定的路径已经存在文件,则抛出异常,这是写数据默认的模式 |
SaveMode.Append |
数据以追加的方式写入 |
SaveMode.Overwrite |
数据以覆盖的方式写入 |
SaveMode.Ignore |
如果给定的路径已经存在文件,则不做任何操作 |
二、CSV
CSV 是一种常见的文本文件格式,其中每一行表示一条记录,记录中的每个字段用逗号分隔。
2.1 读取CSV文件
自动推断类型读取读取示例:
1 | spark.read.format("csv") |
使用预定义类型:
1 | import org.apache.spark.sql.types.{StructField, StructType, StringType,LongType} |
2.2 写入CSV文件
1 | df.write.format("csv").mode("overwrite").save("/tmp/csv/dept2") |
也可以指定具体的分隔符:
1 | df.write.format("csv").mode("overwrite").option("sep", "\t").save("/tmp/csv/dept2") |
2.3 可选配置
为节省主文篇幅,所有读写配置项见文末 9.1 小节。
三、JSON
3.1 读取JSON文件
1 | spark.read.format("json").option("mode", "FAILFAST").load("/usr/file/json/dept.json").show(5) |
需要注意的是:默认不支持一条数据记录跨越多行 (如下),可以通过配置 multiLine 为 true 来进行更改,其默认值为 false。
1 | // 默认支持单行 |
3.2 写入JSON文件
1 | df.write.format("json").mode("overwrite").save("/tmp/spark/json/dept") |
3.3 可选配置
为节省主文篇幅,所有读写配置项见文末 9.2 小节。
四、Parquet
Parquet 是一个开源的面向列的数据存储,它提供了多种存储优化,允许读取单独的列非整个文件,这不仅节省了存储空间而且提升了读取效率,它是 Spark 是默认的文件格式。
4.1 读取Parquet文件
1 | spark.read.format("parquet").load("/usr/file/parquet/dept.parquet").show(5) |
2.2 写入Parquet文件
1 | df.write.format("parquet").mode("overwrite").save("/tmp/spark/parquet/dept") |
2.3 可选配置
Parquet 文件有着自己的存储规则,因此其可选配置项比较少,常用的有如下两个:
| 读写操作 | 配置项 | 可选值 | 默认值 | 描述 |
|---|---|---|---|---|
| Write | compression or codec | None,uncompressed, bzip2, deflate, gzip, lz4, or snappy | None | 压缩文件格式 |
| Read | mergeSchema | true, false | 取决于配置项 spark.sql.parquet.mergeSchema |
当为真时,Parquet 数据源将所有数据文件收集的 Schema 合并在一起,否则将从摘要文件中选择 Schema,如果没有可用的摘要文件,则从随机数据文件中选择 Schema。 |
更多可选配置可以参阅官方文档:https://spark.apache.org/docs/latest/sql-data-sources-parquet.html
五、ORC
ORC 是一种自描述的、类型感知的列文件格式,它针对大型数据的读写进行了优化,也是大数据中常用的文件格式。
5.1 读取ORC文件
1 | spark.read.format("orc").load("/usr/file/orc/dept.orc").show(5) |
4.2 写入ORC文件
1 | csvFile.write.format("orc").mode("overwrite").save("/tmp/spark/orc/dept") |
六、SQL Databases
Spark 同样支持与传统的关系型数据库进行数据读写。但是 Spark 程序默认是没有提供数据库驱动的,所以在使用前需要将对应的数据库驱动上传到安装目录下的 jars 目录中。下面示例使用的是 Mysql 数据库,使用前需要将对应的 mysql-connector-java-x.x.x.jar 上传到 jars 目录下。
6.1 读取数据
读取全表数据示例如下,这里的 help_keyword 是 mysql 内置的字典表,只有 help_keyword_id 和 name 两个字段。
1 | spark.read |
从查询结果读取数据:
1 | val pushDownQuery = """(SELECT * FROM help_keyword WHERE help_keyword_id <20) AS help_keywords""" |
也可以使用如下的写法进行数据的过滤:
1 | val props = new java.util.Properties |
可以使用 numPartitions 指定读取数据的并行度:
1 | option("numPartitions", 10) |
在这里,除了可以指定分区外,还可以设置上界和下界,任何小于下界的值都会被分配在第一个分区中,任何大于上界的值都会被分配在最后一个分区中。
1 | val colName = "help_keyword_id" //用于判断上下界的列 |
想要验证分区内容,可以使用 mapPartitionsWithIndex 这个算子,代码如下:
1 | jdbcDf.rdd.mapPartitionsWithIndex((index, iterator) => { |
执行结果如下:help_keyword 这张表只有 600 条左右的数据,本来数据应该均匀分布在 10 个分区,但是 0 分区里面却有 319 条数据,这是因为设置了下限,所有小于 300 的数据都会被限制在第一个分区,即 0 分区。同理所有大于 500 的数据被分配在 9 分区,即最后一个分区。
6.2 写入数据
1 | val df = spark.read.format("json").load("/usr/file/json/emp.json") |
七、Text
Text 文件在读写性能方面并没有任何优势,且不能表达明确的数据结构,所以其使用的比较少,读写操作如下:
7.1 读取Text数据
1 | spark.read.textFile("/usr/file/txt/dept.txt").show() |
7.2 写入Text数据
1 | df.write.text("/tmp/spark/txt/dept") |
八、数据读写高级特性
8.1 并行读
多个 Executors 不能同时读取同一个文件,但它们可以同时读取不同的文件。这意味着当您从一个包含多个文件的文件夹中读取数据时,这些文件中的每一个都将成为 DataFrame 中的一个分区,并由可用的 Executors 并行读取。
8.2 并行写
写入的文件或数据的数量取决于写入数据时 DataFrame 拥有的分区数量。默认情况下,每个数据分区写一个文件。
8.3 分区写入
分区和分桶这两个概念和 Hive 中分区表和分桶表是一致的。都是将数据按照一定规则进行拆分存储。需要注意的是 partitionBy 指定的分区和 RDD 中分区不是一个概念:这里的分区表现为输出目录的子目录,数据分别存储在对应的子目录中。
1 | val df = spark.read.format("json").load("/usr/file/json/emp.json") |
输出结果如下:可以看到输出被按照部门编号分为三个子目录,子目录中才是对应的输出文件。

8.3 分桶写入
分桶写入就是将数据按照指定的列和桶数进行散列,目前分桶写入只支持保存为表,实际上这就是 Hive 的分桶表。
1 | val numberBuckets = 10 |
8.5 文件大小管理
如果写入产生小文件数量过多,这时会产生大量的元数据开销。Spark 和 HDFS 一样,都不能很好的处理这个问题,这被称为“small file problem”。同时数据文件也不能过大,否则在查询时会有不必要的性能开销,因此要把文件大小控制在一个合理的范围内。
在上文我们已经介绍过可以通过分区数量来控制生成文件的数量,从而间接控制文件大小。Spark 2.2 引入了一种新的方法,以更自动化的方式控制文件大小,这就是 maxRecordsPerFile 参数,它允许你通过控制写入文件的记录数来控制文件大小。
1 | // Spark 将确保文件最多包含 5000 条记录 |
九、可选配置附录
9.1 CSV读写可选配置
| 读\写操作 | 配置项 | 可选值 | 默认值 | 描述 |
|---|---|---|---|---|
| Both | seq | 任意字符 | ,(逗号) |
分隔符 |
| Both | header | true, false | false | 文件中的第一行是否为列的名称。 |
| Read | escape | 任意字符 | \ | 转义字符 |
| Read | inferSchema | true, false | false | 是否自动推断列类型 |
| Read | ignoreLeadingWhiteSpace | true, false | false | 是否跳过值前面的空格 |
| Both | ignoreTrailingWhiteSpace | true, false | false | 是否跳过值后面的空格 |
| Both | nullValue | 任意字符 | “” | 声明文件中哪个字符表示空值 |
| Both | nanValue | 任意字符 | NaN | 声明哪个值表示 NaN 或者缺省值 |
| Both | positiveInf | 任意字符 | Inf | 正无穷 |
| Both | negativeInf | 任意字符 | -Inf | 负无穷 |
| Both | compression or codec | None, uncompressed, bzip2, deflate, gzip, lz4, or snappy |
none | 文件压缩格式 |
| Both | dateFormat | 任何能转换为 Java 的 SimpleDataFormat 的字符串 |
yyyy-MM-dd | 日期格式 |
| Both | timestampFormat | 任何能转换为 Java 的 SimpleDataFormat 的字符串 |
yyyy-MMdd’T’HH:mm:ss.SSSZZ | 时间戳格式 |
| Read | maxColumns | 任意整数 | 20480 | 声明文件中的最大列数 |
| Read | maxCharsPerColumn | 任意整数 | 1000000 | 声明一个列中的最大字符数。 |
| Read | escapeQuotes | true, false | true | 是否应该转义行中的引号。 |
| Read | maxMalformedLogPerPartition | 任意整数 | 10 | 声明每个分区中最多允许多少条格式错误的数据,超过这个值后格式错误的数据将不会被读取 |
| Write | quoteAll | true, false | false | 指定是否应该将所有值都括在引号中,而不只是转义具有引号字符的值。 |
| Read | multiLine | true, false | false | 是否允许每条完整记录跨域多行 |
9.2 JSON读写可选配置
| 读\写操作 | 配置项 | 可选值 | 默认值 |
|---|---|---|---|
| Both | compression or codec | None, uncompressed, bzip2, deflate, gzip, lz4, or snappy |
none |
| Both | dateFormat | 任何能转换为 Java 的 SimpleDataFormat 的字符串 | yyyy-MM-dd |
| Both | timestampFormat | 任何能转换为 Java 的 SimpleDataFormat 的字符串 | yyyy-MMdd’T’HH:mm:ss.SSSZZ |
| Read | primitiveAsString | true, false | false |
| Read | allowComments | true, false | false |
| Read | allowUnquotedFieldNames | true, false | false |
| Read | allowSingleQuotes | true, false | true |
| Read | allowNumericLeadingZeros | true, false | false |
| Read | allowBackslashEscapingAnyCharacter | true, false | false |
| Read | columnNameOfCorruptRecord | true, false | Value of spark.sql.column&NameOf |
| Read | multiLine | true, false | false |
9.3 数据库读写可选配置
| 属性名称 | 含义 |
|---|---|
| url | 数据库地址 |
| dbtable | 表名称 |
| driver | 数据库驱动 |
| partitionColumn, lowerBound, upperBoun |
分区总数,上界,下界 |
| numPartitions | 可用于表读写并行性的最大分区数。如果要写的分区数量超过这个限制,那么可以调用 coalesce(numpartition) 重置分区数。 |
| fetchsize | 每次往返要获取多少行数据。此选项仅适用于读取数据。 |
| batchsize | 每次往返插入多少行数据,这个选项只适用于写入数据。默认值是 1000。 |
| isolationLevel | 事务隔离级别:可以是 NONE,READ_COMMITTED, READ_UNCOMMITTED,REPEATABLE_READ 或 SERIALIZABLE,即标准事务隔离级别。 默认值是 READ_UNCOMMITTED。这个选项只适用于数据读取。 |
| createTableOptions | 写入数据时自定义创建表的相关配置 |
| createTableColumnTypes | 写入数据时自定义创建列的列类型 |
数据库读写更多配置可以参阅官方文档:https://spark.apache.org/docs/latest/sql-data-sources-jdbc.html
参考资料
- Matei Zaharia, Bill Chambers . Spark: The Definitive Guide[M] . 2018-02
- https://spark.apache.org/docs/latest/sql-data-sources.html
参考资料
SparkSQL常用聚合函数
一、简单聚合
1.1 数据准备
1 | // 需要导入 spark sql 内置的函数包 |
注:emp.json 可以从本仓库的resources 目录下载。
1.2 count
1 | // 计算员工人数 |
1.3 countDistinct
1 | // 计算姓名不重复的员工人数 |
1.4 approx_count_distinct
通常在使用大型数据集时,你可能关注的只是近似值而不是准确值,这时可以使用 approx_count_distinct 函数,并可以使用第二个参数指定最大允许误差。
1 | empDF.select(approx_count_distinct ("ename",0.1)).show() |
1.5 first & last
获取 DataFrame 中指定列的第一个值或者最后一个值。
1 | empDF.select(first("ename"),last("job")).show() |
1.6 min & max
获取 DataFrame 中指定列的最小值或者最大值。
1 | empDF.select(min("sal"),max("sal")).show() |
1.7 sum & sumDistinct
求和以及求指定列所有不相同的值的和。
1 | empDF.select(sum("sal")).show() |
1.8 avg
内置的求平均数的函数。
1 | empDF.select(avg("sal")).show() |
1.9 数学函数
Spark SQL 中还支持多种数学聚合函数,用于通常的数学计算,以下是一些常用的例子:
1 | // 1.计算总体方差、均方差、总体标准差、样本标准差 |
1.10 聚合数据到集合
1 | scala> empDF.agg(collect_set("job"), collect_list("ename")).show() |
二、分组聚合
2.1 简单分组
1 | empDF.groupBy("deptno", "job").count().show() |
2.2 分组聚合
1 | empDF.groupBy("deptno").agg(count("ename").alias("人数"), sum("sal").alias("总工资")).show() |
三、自定义聚合函数
Scala 提供了两种自定义聚合函数的方法,分别如下:
- 有类型的自定义聚合函数,主要适用于 DataSet;
- 无类型的自定义聚合函数,主要适用于 DataFrame。
以下分别使用两种方式来自定义一个求平均值的聚合函数,这里以计算员工平均工资为例。两种自定义方式分别如下:
3.1 有类型的自定义函数
1 | import org.apache.spark.sql.expressions.Aggregator |
自定义聚合函数需要实现的方法比较多,这里以绘图的方式来演示其执行流程,以及每个方法的作用:
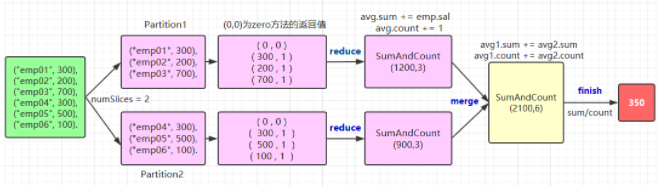
关于 zero,reduce,merge,finish 方法的作用在上图都有说明,这里解释一下中间类型和输出类型的编码转换,这个写法比较固定,基本上就是两种情况:
- 自定义类型 Case Class 或者元组就使用
Encoders.product方法; - 基本类型就使用其对应名称的方法,如
scalaByte,scalaFloat,scalaShort等,示例如下:
1 | override def bufferEncoder: Encoder[SumAndCount] = Encoders.product |
3.2 无类型的自定义聚合函数
理解了有类型的自定义聚合函数后,无类型的定义方式也基本相同,代码如下:
1 | import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction} |
参考资料
- Matei Zaharia, Bill Chambers . Spark: The Definitive Guide[M] . 2018-02
SparkSQL联结操作
一、 数据准备
本文主要介绍 Spark SQL 的多表连接,需要预先准备测试数据。分别创建员工和部门的 Datafame,并注册为临时视图,代码如下:
1 | val spark = SparkSession.builder().appName("aggregations").master("local[2]").getOrCreate() |
两表的主要字段如下:
1 | emp 员工表 |
1 | dept 部门表 |
注:emp.json,dept.json 可以在本仓库的resources 目录进行下载。
二、连接类型
Spark 中支持多种连接类型:
- Inner Join : 内连接;
- Full Outer Join : 全外连接;
- Left Outer Join : 左外连接;
- Right Outer Join : 右外连接;
- Left Semi Join : 左半连接;
- Left Anti Join : 左反连接;
- Natural Join : 自然连接;
- Cross (or Cartesian) Join : 交叉 (或笛卡尔) 连接。
其中内,外连接,笛卡尔积均与普通关系型数据库中的相同,如下图所示:

这里解释一下左半连接和左反连接,这两个连接等价于关系型数据库中的 IN 和 NOT IN 字句:
1 | -- LEFT SEMI JOIN |
所有连接类型的示例代码如下:
2.1 INNER JOIN
1 | // 1.定义连接表达式 |
2.2 FULL OUTER JOIN
1 | empDF.join(deptDF, joinExpression, "outer").show() |
2.3 LEFT OUTER JOIN
1 | empDF.join(deptDF, joinExpression, "left_outer").show() |
2.4 RIGHT OUTER JOIN
1 | empDF.join(deptDF, joinExpression, "right_outer").show() |
2.5 LEFT SEMI JOIN
1 | empDF.join(deptDF, joinExpression, "left_semi").show() |
2.6 LEFT ANTI JOIN
1 | empDF.join(deptDF, joinExpression, "left_anti").show() |
2.7 CROSS JOIN
1 | empDF.join(deptDF, joinExpression, "cross").show() |
2.8 NATURAL JOIN
自然连接是在两张表中寻找那些数据类型和列名都相同的字段,然后自动地将他们连接起来,并返回所有符合条件的结果。
1 | spark.sql("SELECT * FROM emp NATURAL JOIN dept").show() |
以下是一个自然连接的查询结果,程序自动推断出使用两张表都存在的 dept 列进行连接,其实际等价于:
1 | spark.sql("SELECT * FROM emp JOIN dept ON emp.deptno = dept.deptno").show() |
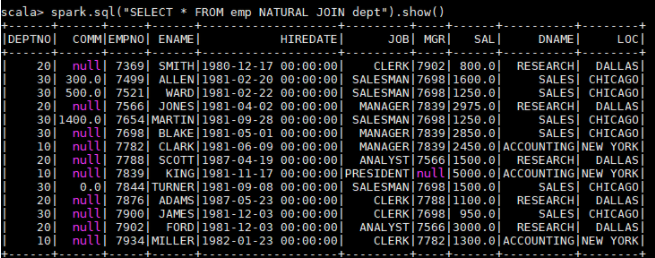
由于自然连接常常会产生不可预期的结果,所以并不推荐使用。
三、连接的执行
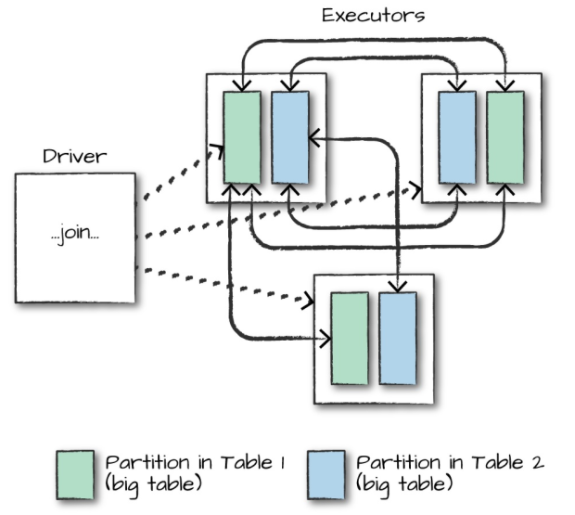
在对大表与大表之间进行连接操作时,通常都会触发 Shuffle Join,两表的所有分区节点会进行 All-to-All 的通讯,这种查询通常比较昂贵,会对网络 IO 会造成比较大的负担。
而对于大表和小表的连接操作,Spark 会在一定程度上进行优化,如果小表的数据量小于 Worker Node 的内存空间,Spark 会考虑将小表的数据广播到每一个 Worker Node,在每个工作节点内部执行连接计算,这可以降低网络的 IO,但会加大每个 Worker Node 的 CPU 负担。
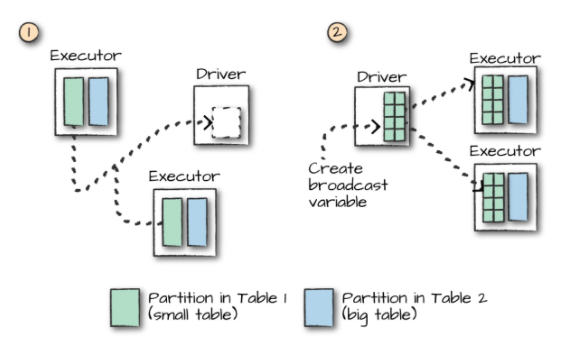
是否采用广播方式进行 Join 取决于程序内部对小表的判断,如果想明确使用广播方式进行 Join,则可以在 DataFrame API 中使用 broadcast 方法指定需要广播的小表:
1 | empDF.join(broadcast(deptDF), joinExpression).show() |
Spark Streaming与流处理
一、流处理
1.1 静态数据处理
在流处理之前,数据通常存储在数据库,文件系统或其他形式的存储系统中。应用程序根据需要查询数据或计算数据。这就是传统的静态数据处理架构。Hadoop 采用 HDFS 进行数据存储,采用 MapReduce 进行数据查询或分析,这就是典型的静态数据处理架构。

1.2 流处理
而流处理则是直接对运动中的数据的处理,在接收数据时直接计算数据。
大多数数据都是连续的流:传感器事件,网站上的用户活动,金融交易等等 ,所有这些数据都是随着时间的推移而创建的。
接收和发送数据流并执行应用程序或分析逻辑的系统称为流处理器。流处理器的基本职责是确保数据有效流动,同时具备可扩展性和容错能力,Storm 和 Flink 就是其代表性的实现。
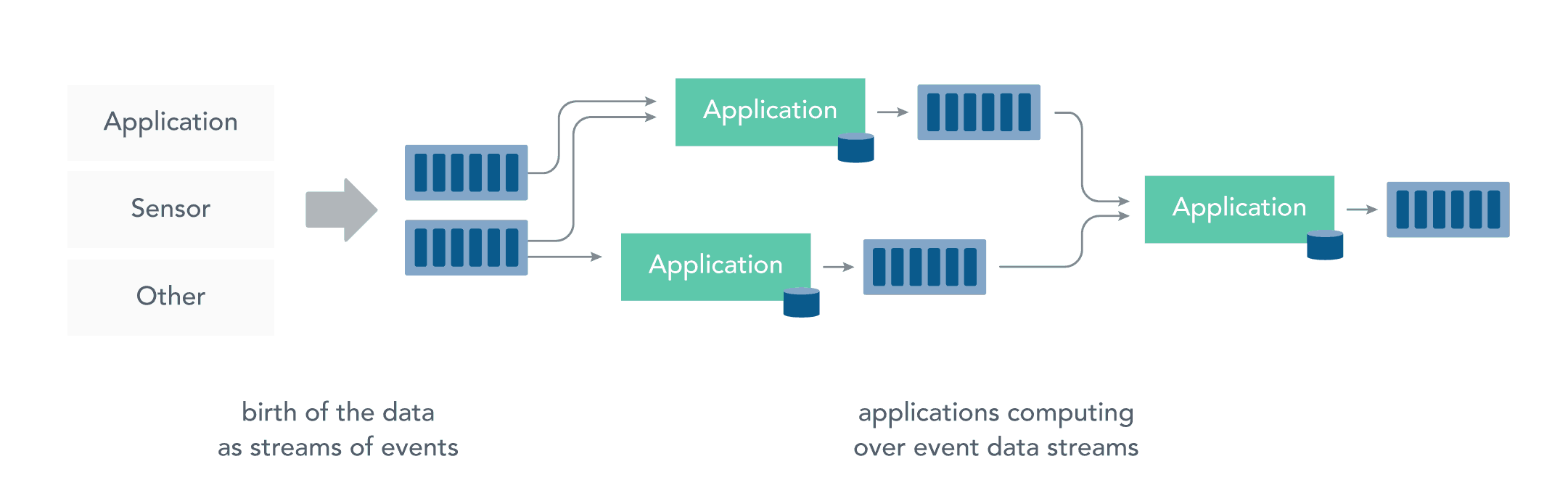
流处理带来了静态数据处理所不具备的众多优点:
- 应用程序立即对数据做出反应:降低了数据的滞后性,使得数据更具有时效性,更能反映对未来的预期;
- 流处理可以处理更大的数据量:直接处理数据流,并且只保留数据中有意义的子集,并将其传送到下一个处理单元,逐级过滤数据,降低需要处理的数据量,从而能够承受更大的数据量;
- 流处理更贴近现实的数据模型:在实际的环境中,一切数据都是持续变化的,要想能够通过过去的数据推断未来的趋势,必须保证数据的不断输入和模型的不断修正,典型的就是金融市场、股票市场,流处理能更好的应对这些数据的连续性的特征和及时性的需求;
- 流处理分散和分离基础设施:流式处理减少了对大型数据库的需求。相反,每个流处理程序通过流处理框架维护了自己的数据和状态,这使得流处理程序更适合微服务架构。
二、Spark Streaming
一、流处理
1.1 静态数据处理
在流处理之前,数据通常存储在数据库,文件系统或其他形式的存储系统中。应用程序根据需要查询数据或计算数据。这就是传统的静态数据处理架构。Hadoop 采用 HDFS 进行数据存储,采用 MapReduce 进行数据查询或分析,这就是典型的静态数据处理架构。
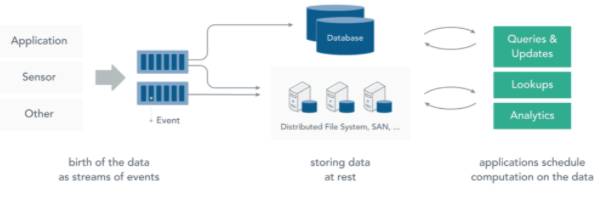
1.2 流处理
而流处理则是直接对运动中的数据的处理,在接收数据时直接计算数据。
大多数数据都是连续的流:传感器事件,网站上的用户活动,金融交易等等 ,所有这些数据都是随着时间的推移而创建的。
接收和发送数据流并执行应用程序或分析逻辑的系统称为流处理器。流处理器的基本职责是确保数据有效流动,同时具备可扩展性和容错能力,Storm 和 Flink 就是其代表性的实现。
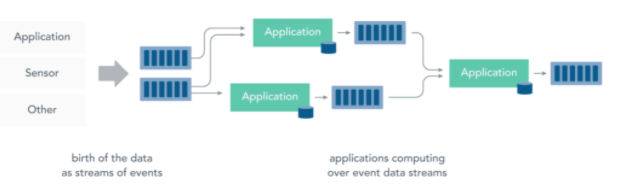
流处理带来了静态数据处理所不具备的众多优点:
- 应用程序立即对数据做出反应:降低了数据的滞后性,使得数据更具有时效性,更能反映对未来的预期;
- 流处理可以处理更大的数据量:直接处理数据流,并且只保留数据中有意义的子集,并将其传送到下一个处理单元,逐级过滤数据,降低需要处理的数据量,从而能够承受更大的数据量;
- 流处理更贴近现实的数据模型:在实际的环境中,一切数据都是持续变化的,要想能够通过过去的数据推断未来的趋势,必须保证数据的不断输入和模型的不断修正,典型的就是金融市场、股票市场,流处理能更好的应对这些数据的连续性的特征和及时性的需求;
- 流处理分散和分离基础设施:流式处理减少了对大型数据库的需求。相反,每个流处理程序通过流处理框架维护了自己的数据和状态,这使得流处理程序更适合微服务架构。
2.1 简介
Spark Streaming 是 Spark 的一个子模块,用于快速构建可扩展,高吞吐量,高容错的流处理程序。具有以下特点:
- 通过高级 API 构建应用程序,简单易用;
- 支持多种语言,如 Java,Scala 和 Python;
- 良好的容错性,Spark Streaming 支持快速从失败中恢复丢失的操作状态;
- 能够和 Spark 其他模块无缝集成,将流处理与批处理完美结合;
- Spark Streaming 可以从 HDFS,Flume,Kafka,Twitter 和 ZeroMQ 读取数据,也支持自定义数据源。

2.2 DStream
Spark Streaming 提供称为离散流 (DStream) 的高级抽象,用于表示连续的数据流。 DStream 可以从来自 Kafka,Flume 和 Kinesis 等数据源的输入数据流创建,也可以由其他 DStream 转化而来。在内部,DStream 表示为一系列 RDD。
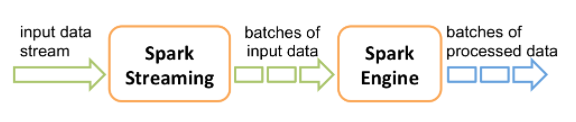
2.3 Spark & Storm & Flink
storm 和 Flink 都是真正意义上的流计算框架,但 Spark Streaming 只是将数据流进行极小粒度的拆分,拆分为多个批处理,使得其能够得到接近于流处理的效果,但其本质上还是批处理(或微批处理)。
参考资料
Spark Streaming 基本操作
一、案例
演示流的创建:获取指定端口上的数据进行词频统计。
项目依赖:
1 | <dependency> |
1 | import org.apache.spark.SparkConf |
可以直接执行官方示例:
1 | $ ./bin/run-example streaming.NetworkWordCount localhost 9999 |
参考: https://spark-reference-doc-cn.readthedocs.io/zh_CN/latest/programming-guide/streaming-guide.html
Spark Streaming 基本操作
一、案例引入
这里先引入一个基本的案例来演示流的创建:获取指定端口上的数据并进行词频统计。项目依赖和代码实现如下:
1 | <dependency> |
1 | import org.apache.spark.SparkConf |
使用本地模式启动 Spark 程序,然后使用 nc -lk 9999 打开端口并输入测试数据:
1 | [root@hadoop001 ~]# nc -lk 9999 |
此时控制台输出如下,可以看到已经接收到数据并按行进行了词频统计。
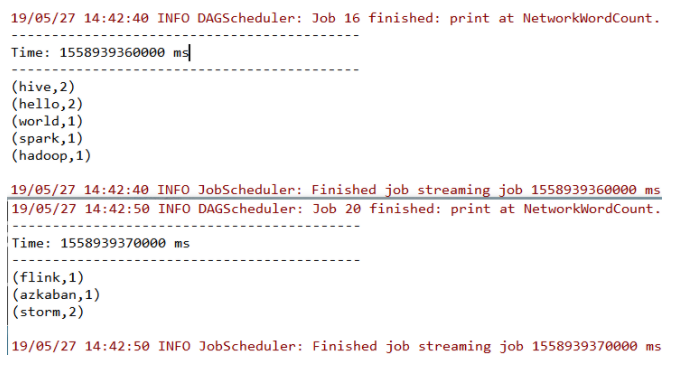
下面针对示例代码进行讲解:
3.1 StreamingContext
Spark Streaming 编程的入口类是 StreamingContext,在创建时候需要指明 sparkConf 和 batchDuration(批次时间),Spark 流处理本质是将流数据拆分为一个个批次,然后进行微批处理,batchDuration 就是批次拆分的时间间隔。这个时间可以根据业务需求和服务器性能进行指定,如果业务要求低延迟并且服务器性能也允许,则这个时间可以指定得很短。
这里需要注意的是:示例代码使用的是本地模式,配置为 local[2],这里不能配置为 local[1]。这是因为对于流数据的处理,Spark 必须有一个独立的 Executor 来接收数据,然后再由其他的 Executors 来处理,所以为了保证数据能够被处理,至少要有 2 个 Executors。这里我们的程序只有一个数据流,在并行读取多个数据流的时候,也需要保证有足够的 Executors 来接收和处理数据。
3.2 数据源
在示例代码中使用的是 socketTextStream 来创建基于 Socket 的数据流,实际上 Spark 还支持多种数据源,分为以下两类:
- 基本数据源:包括文件系统、Socket 连接等;
- 高级数据源:包括 Kafka,Flume,Kinesis 等。
在基本数据源中,Spark 支持监听 HDFS 上指定目录,当有新文件加入时,会获取其文件内容作为输入流。创建方式如下:
1 | // 对于文本文件,指明监听目录即可 |
被监听的目录可以是具体目录,如 hdfs://host:8040/logs/;也可以使用通配符,如 hdfs://host:8040/logs/2017/*。
关于高级数据源的整合单独整理至:Spark Streaming 整合 Flume 和 Spark Streaming 整合 Kafka
3.3 服务的启动与停止
在示例代码中,使用 streamingContext.start() 代表启动服务,此时还要使用 streamingContext.awaitTermination() 使服务处于等待和可用的状态,直到发生异常或者手动使用 streamingContext.stop() 进行终止。
二、Transformation
2.1 DStream与RDDs
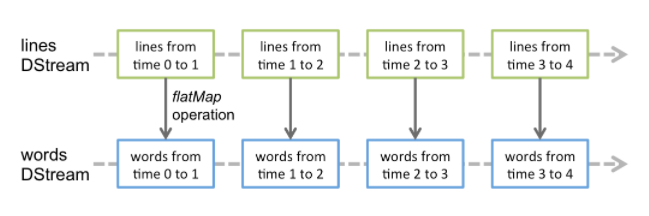
DStream 是 Spark Streaming 提供的基本抽象。它表示连续的数据流。在内部,DStream 由一系列连续的 RDD 表示。所以从本质上而言,应用于 DStream 的任何操作都会转换为底层 RDD 上的操作。例如,在示例代码中 flatMap 算子的操作实际上是作用在每个 RDDs 上 (如下图)。因为这个原因,所以 DStream 能够支持 RDD 大部分的transformation算子。
2.2 updateStateByKey
除了能够支持 RDD 的算子外,DStream 还有部分独有的transformation算子,这当中比较常用的是 updateStateByKey。文章开头的词频统计程序,只能统计每一次输入文本中单词出现的数量,想要统计所有历史输入中单词出现的数量,可以使用 updateStateByKey 算子。代码如下:
1 | object NetworkWordCountV2 { |
使用 updateStateByKey 算子,你必须使用 ssc.checkpoint() 设置检查点,这样当使用 updateStateByKey 算子时,它会去检查点中取出上一次保存的信息,并使用自定义的 updateFunction 函数将上一次的数据和本次数据进行相加,然后返回。
2.3 启动测试
在监听端口输入如下测试数据:
1 | [root@hadoop001 ~]# nc -lk 9999 |
此时控制台输出如下,所有输入都被进行了词频累计:
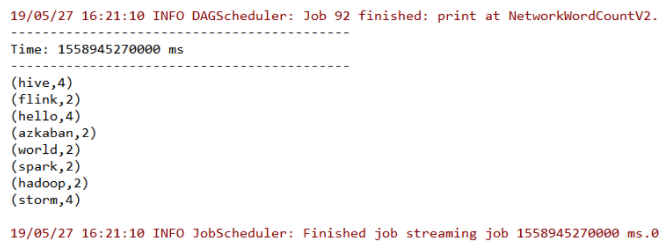
同时在输出日志中还可以看到检查点操作的相关信息:
1 | 保存检查点信息 |
三、输出操作
3.1 输出API
Spark Streaming 支持以下输出操作:
| Output Operation | Meaning |
|---|---|
| print() | 在运行流应用程序的 driver 节点上打印 DStream 中每个批次的前十个元素。用于开发调试。 |
| saveAsTextFiles(prefix, [suffix]) | 将 DStream 的内容保存为文本文件。每个批处理间隔的文件名基于前缀和后缀生成:“prefix-TIME_IN_MS [.suffix]”。 |
| saveAsObjectFiles(prefix, [suffix]) | 将 DStream 的内容序列化为 Java 对象,并保存到 SequenceFiles。每个批处理间隔的文件名基于前缀和后缀生成:“prefix-TIME_IN_MS [.suffix]”。 |
| saveAsHadoopFiles(prefix, [suffix]) | 将 DStream 的内容保存为 Hadoop 文件。每个批处理间隔的文件名基于前缀和后缀生成:“prefix-TIME_IN_MS [.suffix]”。 |
| foreachRDD(func) | 最通用的输出方式,它将函数 func 应用于从流生成的每个 RDD。此函数应将每个 RDD 中的数据推送到外部系统,例如将 RDD 保存到文件,或通过网络将其写入数据库。 |
前面的四个 API 都是直接调用即可,下面主要讲解通用的输出方式 foreachRDD(func),通过该 API 你可以将数据保存到任何你需要的数据源。
3.1 foreachRDD
这里我们使用 Redis 作为客户端,对文章开头示例程序进行改变,把每一次词频统计的结果写入到 Redis,并利用 Redis 的 HINCRBY 命令来进行词频统计。这里需要导入 Jedis 依赖:
1 | <dependency> |
具体实现代码如下:
1 | import org.apache.spark.SparkConf |
其中 JedisPoolUtil 的代码如下:
1 | import redis.clients.jedis.Jedis; |
3.3 代码说明
这里将上面保存到 Redis 的代码单独抽取出来,并去除异常判断的部分。精简后的代码如下:
1 | pairs.foreachRDD { rdd => |
这里可以看到一共使用了三次循环,分别是循环 RDD,循环分区,循环每条记录,上面我们的代码是在循环分区的时候获取连接,也就是为每一个分区获取一个连接。但是这里大家可能会有疑问:为什么不在循环 RDD 的时候,为每一个 RDD 获取一个连接,这样所需要的连接数会更少。实际上这是不可行的,如果按照这种情况进行改写,如下:
1 | pairs.foreachRDD { rdd => |
此时在执行时候就会抛出 Caused by: java.io.NotSerializableException: redis.clients.jedis.Jedis,这是因为在实际计算时,Spark 会将对 RDD 操作分解为多个 Task,Task 运行在具体的 Worker Node 上。在执行之前,Spark 会对任务进行闭包,之后闭包被序列化并发送给每个 Executor,而 Jedis 显然是不能被序列化的,所以会抛出异常。
第二个需要注意的是 ConnectionPool 最好是一个静态,惰性初始化连接池 。这是因为 Spark 的转换操作本身就是惰性的,且没有数据流时不会触发写出操作,所以出于性能考虑,连接池应该是惰性的,因此上面 JedisPool 在初始化时采用了懒汉式单例进行惰性初始化。
3.4 启动测试
在监听端口输入如下测试数据:
1 | [root@hadoop001 ~]# nc -lk 9999 |
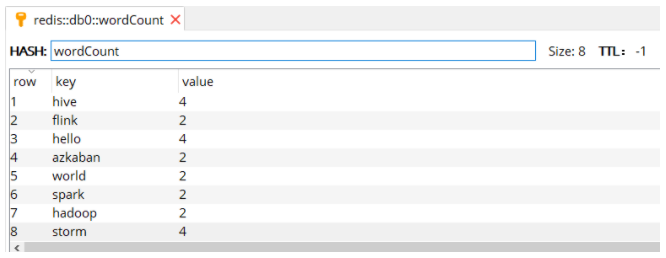
使用 Redis Manager 查看写入结果 (如下图),可以看到与使用 updateStateByKey 算子得到的计算结果相同。
本片文章所有源码见本仓库:spark-streaming-basis
参考资料
Spark 官方文档:http://spark.apache.org/docs/latest/streaming-programming-guide.html
参考
- https://github.com/RealTommyHu/BigData-Notes/blob/master/notes/Spark简介.md
- https://github.com/RealTommyHu/BigData-Notes/blob/master/notes/Spark_RDD.md
- https://github.com/RealTommyHu/BigData-Notes/blob/master/notes/Spark_Transformation和Action算子.md
- https://github.com/RealTommyHu/BigData-Notes/blob/master/notes/Spark累加器与广播变量.md
- https://github.com/RealTommyHu/BigData-Notes/blob/master/notes/SparkSQL_Dataset和DataFrame简介.md
- https://github.com/RealTommyHu/BigData-Notes/blob/master/notes/Spark_Structured_API的基本使用.md
- https://github.com/RealTommyHu/BigData-Notes/blob/master/notes/SparkSQL外部数据源.md
- https://github.com/RealTommyHu/BigData-Notes/blob/master/notes/SparkSQL常用聚合函数.md
- https://github.com/RealTommyHu/BigData-Notes/blob/master/notes/SparkSQL联结操作.md
- https://github.com/RealTommyHu/BigData-Notes/blob/master/notes/Spark_Streaming与流处理.md
- https://github.com/RealTommyHu/BigData-Notes/blob/master/notes/Spark_Streaming基本操作.md